58 vis-gapminder
Aufgaben, Statistik, Prognose, Modellierung, R, Datenanalyse, Regression
58.1 Aufgabe
In dieser Fallstudie (YACSDA: Yet another Case Study on Data Analysis) untersuchen wir den Datensatz gapminder.
Sie können den Datensatz so beziehen:
Oder so:
d <- read.csv("https://vincentarelbundock.github.io/Rdatasets/csv/gapminder/gapminder.csv")Ein Codebook finden Sie hier.
Die Forschungsfrage lautet:
Was ist der Einfluss des Kontinents und des Bruttosozialprodukts auf die Lebenswartung?
- Abhängige Variable (metrisch),
y: Lebenserwartung - Unabhängige Variable 1 (nominal),
x1: Kontinent - Unabhängige Variable 2 (metrisch),
x2: Bruttosozialprodukt
Visualisieren Sie dazu folgende Aspekte der Forschungsfrage!
58.2 Aufgaben
- Visualisieren Sie die Verteilung von
yauf zwei verschiedene Arten. - Fügen Sie relevante Kennzahlen zur letzten Visualisierung hinzu.
- Visualisieren Sie die Verteilung von
x1undx2. - Visualisieren Sie die Verteilung von
ybedingt aufx1. - Fügen Sie relevante Kennzahlen zur letzten Visualisierung hinzu.
- Visualisieren Sie den Zusammenhang von
yundx2. - Verbessern Sie das letzte Diagramm, so dass es übersichtlicher wird.
- Fügen Sie dem letzten Diagramm relevante Kennzahlen hinzu.
- Fügen Sie dem Diagramm zum Zusammenhang von
yundx2eine Regressionsgerade hinzu. - Ersetzen Sie die Regressionsgerade durch eine LOESS-Gerade.
- Gruppieren Sie das letzte Diagramm nach
x1. - Dichotomisieren Sie
yund zählen Sie die Häufigkeiten. Achtung: Dichotomisieren wird von einigen Statistikern mit Exkommunikation bestraft. Proceed at your own risk. - Gruppieren Sie das letzte Diagramm nach den Stufen von
x1. - Variieren Sie das letzte Diagramm so, dass Anteile (relative Häufigkeiten) statt absoluter Häufigkeiten gezeigt werden.
Hinweise:
- Orientieren Sie sich im Übrigen an den allgemeinen Hinweisen des Datenwerks.
58.3 Lösung
58.4 Pakete starten
58.5 Los geht’s
58.5.1 Umbenennen
Zur einfacheren Verarbeitung nenne ich die Variablen um:
d <-
d |>
rename(y = lifeExp, x1 = continent, x2 = gdpPercap)
58.5.2 Visualisieren Sie die Verteilung von y auf zwei verschiedene Arten.
Das R-Paket ggpubr erstellt schöne Diagramme (basierend auf ggplot) auf einfache Art. Nehmen wir ein Dichtediagramm; die Variable y soll auf der X-Achse stehen:
ggdensity(d, x = "y")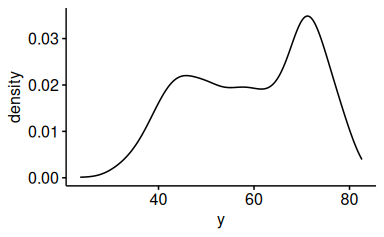
Beachten Sie, dass die Variable in Anführungsstriche gesetzt werden muss: x = "y".
Oder ein Histogramm:
gghistogram(d, x = "y")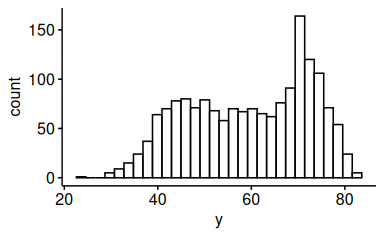
58.5.3 Fügen Sie relevante Kennzahlen zur letzten Visualisierung hinzu.
Um Diagramme mit Statistiken anzureichen, bietet sich das Paket ggstatsplot an:
gghistostats(d, x = y)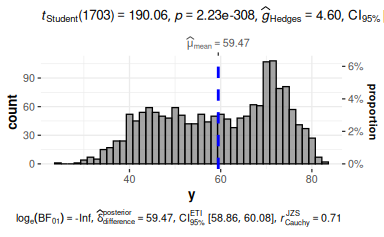
Beachten Sie, dass die Variable nicht in Anführungsstriche gesetzt werden darf: x = y.
58.5.4 Visualisieren Sie die Verteilung von x1 und x2.
58.5.4.1 x1
d_counted <-
d |>
count(x1) ggbarplot(data = d_counted, y = "n", x = "x1", label = TRUE)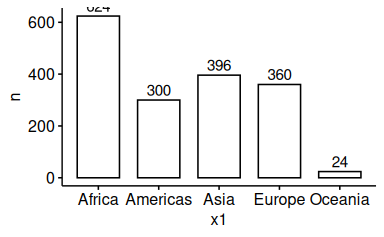
58.5.4.2 x2
gghistostats(d, x = x2)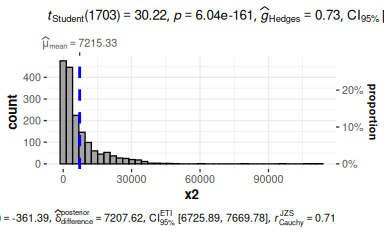
58.5.5 Visualisieren Sie die Verteilung von y bedingt auf x1
gghistogram(d, x = "y", fill = "x1")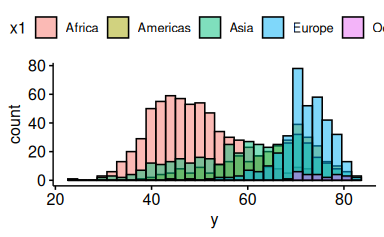
Oder so:
gghistogram(d, x = "y", facet.by = "x1")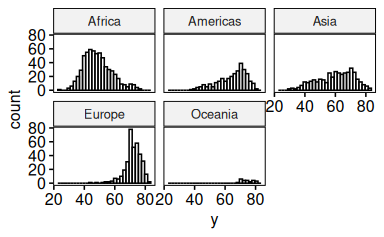
58.5.6 Fügen Sie relevante Kennzahlen zur letzten Visualisierung hinzu
grouped_gghistostats(d, x = y, grouping.var = x1)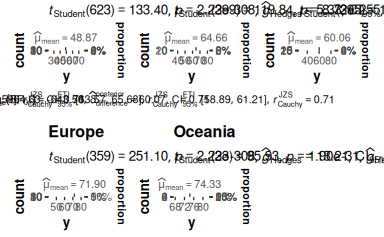
58.5.7 Visualisieren Sie den Zusammenhang von y und x2
ggscatter(d, x = "x2", y = "y")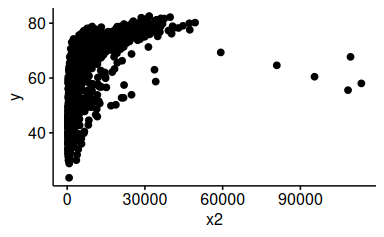
58.5.8 Verbessern Sie das letzte Diagramm, so dass es übersichtlicher wird
Es gibt mehrere Wege, das Diagramm übersichtlicher zu machen. Logarithmieren ist ein Weg.
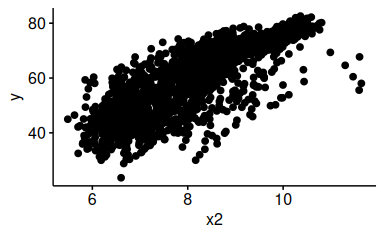
Synonym könnten wir schreiben:
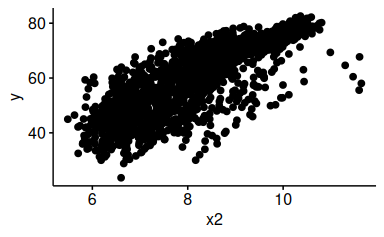
58.5.9 Fügen Sie dem letzten Diagramm relevante Kennzahlen hinzu
ggscatterstats(d_logged, x = "x2", y = "y")
58.5.10 Fügen Sie dem Diagramm zum Zusammenhang von y und x2 eine Regressionsgerade hinzu
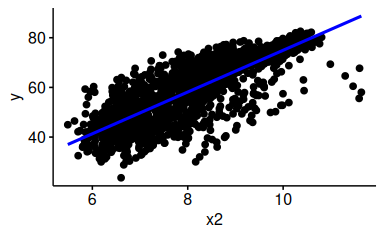
58.5.11 Ersetzen Sie die Regressionsgerade durch eine LOESS-Gerade
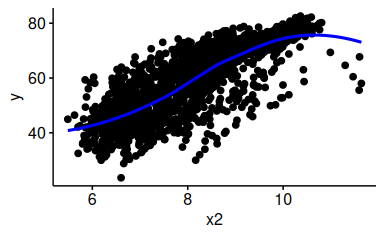
58.5.12 Gruppieren Sie das letzte Diagramm nach x1

58.5.13 Dichotomisieren Sie y und zählen Sie die Häufigkeiten
Nehmen wir einen Mediansplit, um zu dichotomisieren.
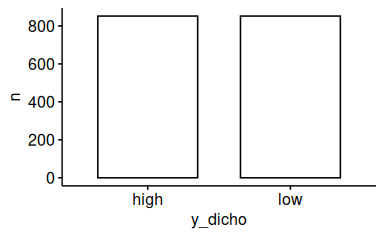
Gleich viele! Das sollte nicht verwundern.
58.5.14 Gruppieren Sie das letzte Diagramm nach den Stufen von x1
d_count <-
d |>
count(y_dicho, x1)
d_countggbarplot(d_count, x = "y_dicho", y = "n", facet.by = "x1")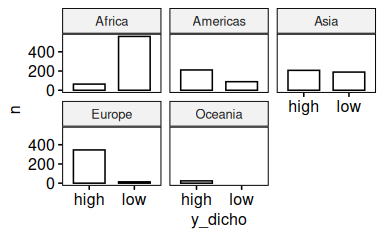
58.5.15 Variieren Sie das letzte Diagramm so, dass Anteile (relative Häufigkeiten) statt absoluter Häufigkeiten gezeigt werden
Check:
Gut! Die Anteile summieren sich zu ca. 1 (100 Prozent).
ggbarplot(d_count, x = "y_dicho", y = "prop", facet.by = "x1", label = TRUE)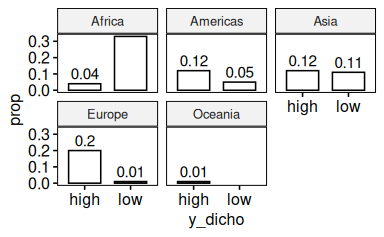
Man beachten, dass sich die Anteile auf das “Gesamt-N” beziehen.
Vielleicht möchten wir die Anteile lieber pro Stufe von x1 beziehen. Dazu gruppieren wir nach (und pro Stufe von) x1.
ggbarplot(d_count, x = "y_dicho", y = "prop", facet.by = "x1", label = TRUE)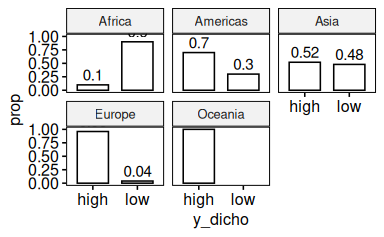
Categories:
- vis
- yacsda
- ggquick
- gapminder
- string