# 12 — Pivot fingerprint
tar_target(
df_long_fingerprint,
{
tic()
tmp <- df_char %>% pivot_longer(
cols = -any_of("fingerprint"),
names_to = "name",
values_to = "value"
)
toc()
tmp
}
),1 Den Überblick behalten mit Pipeline-Tools
1.1 Targets
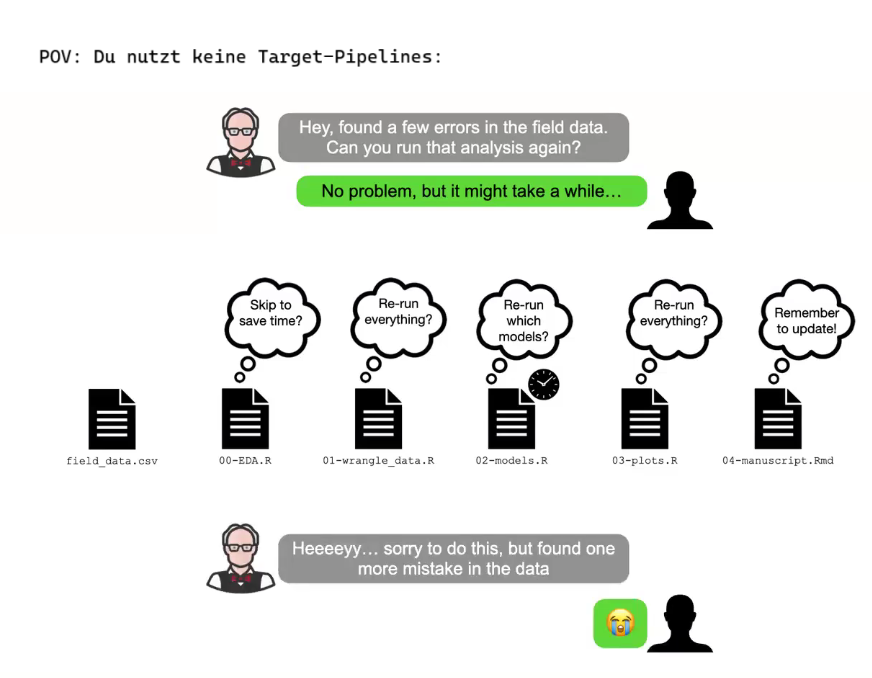
Eine Analyse mit vielen Schritten kann leicht unübersichtlich werden. Ein anderes Problem ist, dass man viele Objekte erzeugt, als Ergebnisse der Zwischenschritte. Ändert man einen Zwischenschritt, so ändert sich der Input für alle darauf folgende Analyseschritte. Man muss also diese neu berechnen. Gefährlich wäre, würde man vergessen, diese Objekte neu zu berechnen: Man würde mit einem “veralteten” also falschen Objekt weiterarbeiten, was zwangsläufig zu falschen Ergebnissen führten würde.
Wäre es nicht schön, wenn es ein Tool gäbe, das für Sie den Überblick behält und dafür sorgt, dass die veralteten Objekte (und nur die) bei Bedarf neu berechnet werden?
Solche Tools gibt es. Wir schauen uns dazu das Tool targets an.
Hier ist ein erstes Beispiel, und hier ist eine weitere Einführung in Targets.
Diese Präsentation führt in Targets ein mit einer Data-Science-Anwendung.
1.2 Tipps
Anstelle von:
besser eine Funktion definieren für das jeweilige Target:
pivot_longer_hardcoded <- function(){
tic()
tmp <- df_char %>% pivot_longer(
cols = -any_of("fingerprint"),
names_to = "name",
values_to = "value"
)
toc()
tmp
}und ann ein kürzeres Target definieren mit der selbstgeschriebenen Funktion:
# 12 — Pivot fingerprint
tar_target(
df_long_fingerprint,
pivot_longer_hardcoded()
),Wiederverwendung
MIT
Zitat
Mit BibTeX zitieren:
@online{untitled,
author = {},
url = {https://sebastiansauer.github.io/hans-hackathon2025/projektmanagement.html},
langid = {de-DE}
}
Bitte zitieren Sie diese Arbeit als: