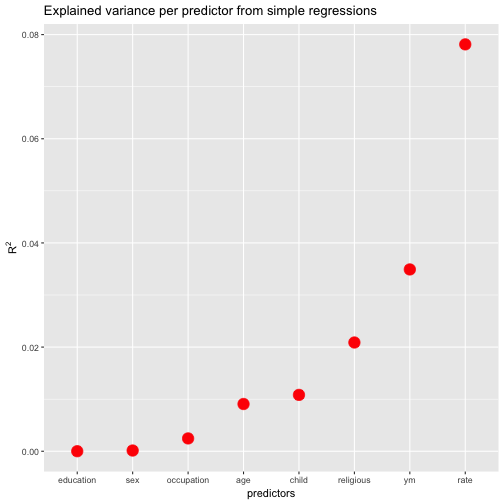
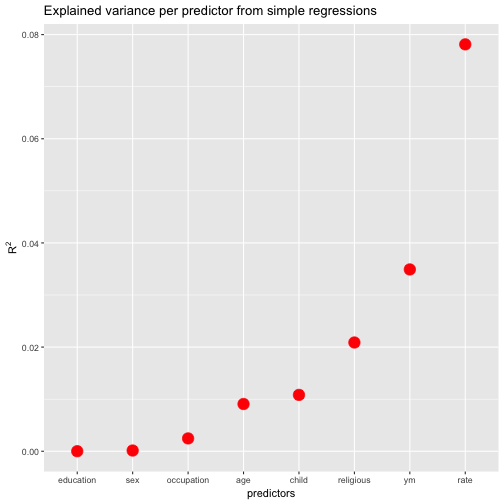
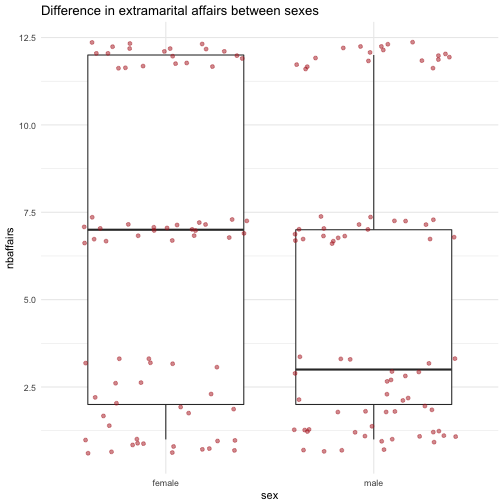
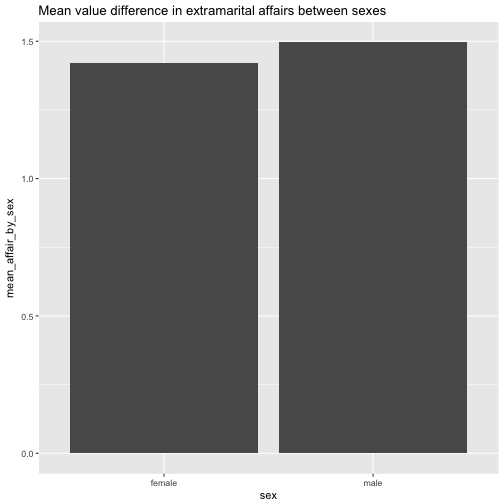
A frequent task in data analysis is to get a summary of a bunch of variables. Often, graphical summaries (diagrams) are wanted. However, at times numerical summaries are in order. How to get that in R? That’s the question of the present post.
Of course, there are several ways. One way, using purrr, is the following. I liked it quite a bit that’s why I am showing it here.
First, let’s load some data and some packages we will make use of.
data(Affairs, package = "AER")
library(purrr)
library(dplyr)
library(broom)
Define two helper functions we will need later on:
add_na_col <- function(x){
mutate(x, na = 0)
}
has_n_col <- function(x, n = 6){
return(ncol(x) == n)
}
Set one value to NA for illustration purposes:
Affairs$affairs[1] <- NA # one NA for illustrative purposes
Now comes the show:
Affairs %>%
select_if(is.numeric) %>%
map(~tidy(summary(.x))) %>% # compute tidy summary of each var
map_if(., has_n_col, add_na_col) %>% # add na-col if missing
do.call(rbind, .) -> Affairs_summary # bind list elements into df
Affairs_summary
## minimum q1 median mean q3 maximum na
## affairs 0.000 0 0 1.458 0.25 12 1
## age 17.500 27 32 32.490 37.00 57 0
## yearsmarried 0.125 4 7 8.178 15.00 15 0
## religiousness 1.000 2 3 3.116 4.00 5 0
## education 9.000 14 16 16.170 18.00 20 0
## occupation 1.000 3 5 4.195 6.00 7 0
## rating 1.000 3 4 3.932 5.00 5 0
What we did was:
- Get the
Affairsdata, and select the numeric columns - Map the
summaryfunction to each column, and tidy up each column. We will get a list of tidy summaries. - If a list element has 6 elements (or columns, because we want to end up with a data frame), then we know there is no
NA-column. In this case,add_na_col, else not. That’s what themap_ifbit does. - Lastly, bind the list elements row wise. To that end, give a bag of summary-elements to
rbindby help ofdo.call.
Instead of purr::map, a more familiar approach would have been this:
Affairs %>%
dplyr::select_if(is.numeric) %>%
lapply(., function(x) tidy(summary(x))) # compute tidy summary of each var
## $affairs
## minimum q1 median mean q3 maximum na
## 1 0 0 0 1.458 0.25 12 1
##
## $age
## minimum q1 median mean q3 maximum
## 1 17.5 27 32 32.49 37 57
##
## $yearsmarried
## minimum q1 median mean q3 maximum
## 1 0.125 4 7 8.178 15 15
##
## $religiousness
## minimum q1 median mean q3 maximum
## 1 1 2 3 3.116 4 5
##
## $education
## minimum q1 median mean q3 maximum
## 1 9 14 16 16.17 18 20
##
## $occupation
## minimum q1 median mean q3 maximum
## 1 1 3 5 4.195 6 7
##
## $rating
## minimum q1 median mean q3 maximum
## 1 1 3 4 3.932 5 5
And, finally, a quite nice formatting tool for html tables is DT:datatable (output not shown):
library(DT)
datatable(Affairs_summary)
Although this approach may not work in each environment, particularly not with knitr (as far as I know of).
That’s why an alternative html table approach is used:
library(htmlTable)
htmlTable(Affairs_summary)
| minimum | q1 | median | mean | q3 | maximum | na | |
|---|---|---|---|---|---|---|---|
| affairs | 0 | 0 | 0 | 1.458 | 0.25 | 12 | 1 |
| age | 17.5 | 27 | 32 | 32.49 | 37 | 57 | 0 |
| yearsmarried | 0.125 | 4 | 7 | 8.178 | 15 | 15 | 0 |
| religiousness | 1 | 2 | 3 | 3.116 | 4 | 5 | 0 |
| education | 9 | 14 | 16 | 16.17 | 18 | 20 | 0 |
| occupation | 1 | 3 | 5 | 4.195 | 6 | 7 | 0 |
| rating | 1 | 3 | 4 | 3.932 | 5 | 5 | 0 |