Hier eine Liste einiger meiner “Lieblings-R-Funktionen”; für Einführungsveranstaltungen in Statistik spielen sie (bei mir) eine wichtige Rolle. Die Liste kann sich ändern :-)
Wenn ich von einer “Tabelle” spreche, meine ich sowohl Dataframes als auch Tibbles.
Zuweisung - <-
Mit dem Zuweisungsoperator <- kann man Objekten einen Wert zuweisen:
x <- 1
mtcars2 <- mtcars
Spalten als Vektor auswählen - $
Mit dem Operator $ kann man eine Spalte einer Tabelle auswählen. Die Spalte wird als Vektor zurückgegeben.
mtcars$hp
## [1] 110 110 93 110 175 105 245 62 95 123 123 180 180 180 205 215 230
## [18] 66 52 65 97 150 150 245 175 66 91 113 264 175 335 109
Struktur eines Objekts ausgeben lassen - str
Die “Struktur” eines Objekts (z.B. einer Tabelle) kann man sich mit str ausgeben lassen:
str(mtcars)
## 'data.frame': 32 obs. of 11 variables:
## $ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
## $ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
## $ disp: num 160 160 108 258 360 ...
## $ hp : num 110 110 93 110 175 105 245 62 95 123 ...
## $ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
## $ wt : num 2.62 2.88 2.32 3.21 3.44 ...
## $ qsec: num 16.5 17 18.6 19.4 17 ...
## $ vs : num 0 0 1 1 0 1 0 1 1 1 ...
## $ am : num 1 1 1 0 0 0 0 0 0 0 ...
## $ gear: num 4 4 4 3 3 3 3 4 4 4 ...
## $ carb: num 4 4 1 1 2 1 4 2 2 4 ...
Die Tabelle mtcars ist ein data.frame mit 32 Fällen und 11 Variablen. Alle Variablen sind numerisch (num).
Werte zu einem Vektor zusammenfügen - c
Einzelne Werte kann man man c (wie “combine”) zu einem Vektor zusammenfügen.
x <- c(1,2,3)
x
## [1] 1 2 3
y <- c(1)
z <- c("Anna", "Berta", "Carla")
Zu beachten ist, dass ein Vektor nur einen Typ von Daten (z.B. nur Text oder nur reelle Zahlen) enthalten kann. Im Zweifel macht R aus dem Vektor einen Text-Vektor.
Nur die ersten Zeilen einer Tabelle anzeigen - head
Mit head kann man sich die ersten Zeilen einer Tabelle anzeigen lassen:
head(mtcars) # 6 Zeilen sind der Default-Wert
## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
head(mtcars, 3) # nur die ersten 3 Zeilen etc.
## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Spalten auswählen - dplyr::select
Spalten kann man mit select auswählen:
library(tidyverse) # oder: library(dplyr)
select(mtcars, hp, cyl)
## hp cyl
## Mazda RX4 110 6
## Mazda RX4 Wag 110 6
## Datsun 710 93 4
## Hornet 4 Drive 110 6
## Hornet Sportabout 175 8
## Valiant 105 6
## Duster 360 245 8
## Merc 240D 62 4
## Merc 230 95 4
## Merc 280 123 6
## Merc 280C 123 6
## Merc 450SE 180 8
## Merc 450SL 180 8
## Merc 450SLC 180 8
## Cadillac Fleetwood 205 8
## Lincoln Continental 215 8
## Chrysler Imperial 230 8
## Fiat 128 66 4
## Honda Civic 52 4
## Toyota Corolla 65 4
## Toyota Corona 97 4
## Dodge Challenger 150 8
## AMC Javelin 150 8
## Camaro Z28 245 8
## Pontiac Firebird 175 8
## Fiat X1-9 66 4
## Porsche 914-2 91 4
## Lotus Europa 113 4
## Ford Pantera L 264 8
## Ferrari Dino 175 6
## Maserati Bora 335 8
## Volvo 142E 109 4
Zeilen filtern - dplyr::filter
Zeilen filtern kann man mit filter:
filter(mtcars, hp > 200, cyl > 6)
## mpg cyl disp hp drat wt qsec vs am gear carb
## 1 14.3 8 360 245 3.21 3.570 15.84 0 0 3 4
## 2 10.4 8 472 205 2.93 5.250 17.98 0 0 3 4
## 3 10.4 8 460 215 3.00 5.424 17.82 0 0 3 4
## 4 14.7 8 440 230 3.23 5.345 17.42 0 0 3 4
## 5 13.3 8 350 245 3.73 3.840 15.41 0 0 3 4
## 6 15.8 8 351 264 4.22 3.170 14.50 0 1 5 4
## 7 15.0 8 301 335 3.54 3.570 14.60 0 1 5 8
Zeilen sortieren - dplyr::arrange
Mit arrange kann man eine Tabelle nach einer Spalte filtern.
mtcars_sortiert <- arrange(mtcars, -cyl)
head(mtcars_sortiert, 3)
## mpg cyl disp hp drat wt qsec vs am gear carb
## 1 18.7 8 360.0 175 3.15 3.44 17.02 0 0 3 2
## 2 14.3 8 360.0 245 3.21 3.57 15.84 0 0 3 4
## 3 16.4 8 275.8 180 3.07 4.07 17.40 0 0 3 3
arrange sortiert als Default aufsteigend. Möchte man absteigend sortieren, kann man ein Minuszeichen vor der zu sortierenden Variable stellen.
Befehle “durchpfeifen” - ` %>% ` (dplyr)
Befehle “verknüpfen”, d.h. hintereinander ausführen kann man mit ` %>% . Es lassen sich nicht alle Befehle verknüpfen, sondern nur Befehle, die eine Tabelle als Input und als Output vorsehen. Weil der Operator %>% ` auch “pipe” (Pfeife) genannt wird, nenne ich die Anwendung des Operators auch “durchpfeifen”. Man kann ` %>% ` auf Deutsch übersetzen mit “und dann”.
mtcars %>%
select(hp, cyl) %>%
filter(hp > 200) %>%
arrange(-hp)
## hp cyl
## 1 335 8
## 2 264 8
## 3 245 8
## 4 245 8
## 5 230 8
## 6 215 8
## 7 205 8
Diese Befehlskette kann man lesen als:
Nehme die Tabelle “mtcars” UND DANN
wähle die Spalten “hp” und “cyl” UND DANN
filtere nur Zeilen mit mehr als 200 PS UND DANN
sortiere absteigend nach PS.
Das Durchpfeifen ist eine tolle Sache: spart Zeit und ist gut lesbar.
Deskriptive Statistik - mean, sum, sd, median, IQR, max, min, …
Die R-Funktionen der Statistik haben recht selbst erklärende Namen. Sie erwarten einen Vektor (Spalte) als Eingabe.
mean(mtcars$hp)
## [1] 146.6875
max(mtcars$cyl)
## [1] 8
sd(mtcars$hp)
## [1] 68.56287
Deskriptive Statistik - mosaic
Mit dem Package mosaic können eine Reihe komfortabler Funktionen für z.B. die deskriptive Statistik gerechnet werden. Besonders schön ist, dass Gruppierungen sehr einfach sind.
library(mosaic)
mean(hp ~ cyl, data = mtcars) # entsprechend für sd, median,...
## 4 6 8
## 82.63636 122.28571 209.21429
Funktionen aus mosaic sind häufig mit dem “Kringel” Y ~ X aufgebaut. Bei den Befehlen für deskriptive Statistik steht vor dem Kringel die Datei, die analysiert werden soll und nach dem Kringel die Gruppierungsvariable.
Praktisch ist auch die Funktion favstats, die “Favoriten-Statistiken” ausgibt:
favstats(mtcars$hp)
## min Q1 median Q3 max mean sd n missing
## 52 96.5 123 180 335 146.6875 68.56287 32 0
favstats(mtcars$hp ~ mtcars$cyl)
## mtcars$cyl min Q1 median Q3 max mean sd n missing
## 1 4 52 65.50 91.0 96.00 113 82.63636 20.93453 11 0
## 2 6 105 110.00 110.0 123.00 175 122.28571 24.26049 7 0
## 3 8 150 176.25 192.5 241.25 335 209.21429 50.97689 14 0
Grundrechnen (Arithmetik) - +, -, *, /, …
Man kann R als Taschenrechner verwenden.
2*2
## [1] 4
1+1
## [1] 2
6 / 3
## [1] 2
6 / 4
## [1] 1.5
Zu beachten ist, dass R vektoriell rechnet.
Spalten zusammenfassen zu einer Zahl - dplyr::summarise
Der Befehl summarise (aus dplyr) fasst Spalten zu einer Zahl zusammen. Daher verkraftet er auch nur Befehle, die aus einer Spalte eine Zahl machen, z.B. mean, sd etc.
mtcars %>%
summarise(hp_mittelwert = mean(hp))
## hp_mittelwert
## 1 146.6875
# oder
summarise(mtcars, hp_mittelwert = mean(hp))
## hp_mittelwert
## 1 146.6875
Tabellen gruppieren - dplyr::group_by
Häufig möchte man Gruppen vergleichen: Parken Frauen schneller aus als Männer? Haben Autos mit 6 Zylinder im Schnitt mehr PS als solche mit 8?
mtcars %>%
filter(cyl > 4) %>%
group_by(cyl) %>%
summarise(hp_mittelwert = mean(hp))
## # A tibble: 2 × 2
## cyl hp_mittelwert
## <dbl> <dbl>
## 1 6 122.2857
## 2 8 209.2143
Alle dplyr-Befehle verstehen die Gruppierung, die group_by in die Tabelle einfügt. Achtung: Eine mit group_by gruppierte Tabelle sieht genauso aus wie eine nicht-gruppierte Tabelle. Der Effekt macht sich nur in den folgenden Befehlen bemerkbar.
Diagramme erstellen - ggplot2::qplot
Eine flexible Art, Diagramme (“plots”) zu erstellen, ist mit qplot.
library(ggplot2)
qplot(x = cyl, y = hp, data = mtcars)
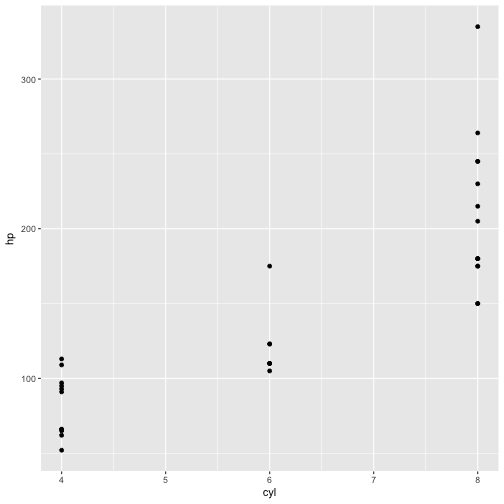
Die wichtigsten Parameter der Funktion sind X-Achse (x), Y-Achse (y) und Name der Tabelle (data).
Korrelationen (bivariat) - cor
cor(mtcars$hp, mtcars$cyl)
## [1] 0.8324475
cor(mpg ~ disp, data = mtcars)
## [1] -0.8475514
Korrelationen (Matrix) - corrr
Mit dem Paket corrr lassen sich komfortabel Korrelationsmatrizen erstellen.
library(corrr)
mtcars %>%
correlate
## # A tibble: 11 × 12
## rowname mpg cyl disp hp drat
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 mpg NA -0.8521620 -0.8475514 -0.7761684 0.68117191
## 2 cyl -0.8521620 NA 0.9020329 0.8324475 -0.69993811
## 3 disp -0.8475514 0.9020329 NA 0.7909486 -0.71021393
## 4 hp -0.7761684 0.8324475 0.7909486 NA -0.44875912
## 5 drat 0.6811719 -0.6999381 -0.7102139 -0.4487591 NA
## 6 wt -0.8676594 0.7824958 0.8879799 0.6587479 -0.71244065
## 7 qsec 0.4186840 -0.5912421 -0.4336979 -0.7082234 0.09120476
## 8 vs 0.6640389 -0.8108118 -0.7104159 -0.7230967 0.44027846
## 9 am 0.5998324 -0.5226070 -0.5912270 -0.2432043 0.71271113
## 10 gear 0.4802848 -0.4926866 -0.5555692 -0.1257043 0.69961013
## 11 carb -0.5509251 0.5269883 0.3949769 0.7498125 -0.09078980
## # ... with 6 more variables: wt <dbl>, qsec <dbl>, vs <dbl>, am <dbl>,
## # gear <dbl>, carb <dbl>
Möchte man das obere Dreieck “abrasieren”, da es redundant ist, so kann man das so machen:
mtcars %>%
correlate %>%
shave
## # A tibble: 11 × 12
## rowname mpg cyl disp hp drat
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 mpg NA NA NA NA NA
## 2 cyl -0.8521620 NA NA NA NA
## 3 disp -0.8475514 0.9020329 NA NA NA
## 4 hp -0.7761684 0.8324475 0.7909486 NA NA
## 5 drat 0.6811719 -0.6999381 -0.7102139 -0.4487591 NA
## 6 wt -0.8676594 0.7824958 0.8879799 0.6587479 -0.71244065
## 7 qsec 0.4186840 -0.5912421 -0.4336979 -0.7082234 0.09120476
## 8 vs 0.6640389 -0.8108118 -0.7104159 -0.7230967 0.44027846
## 9 am 0.5998324 -0.5226070 -0.5912270 -0.2432043 0.71271113
## 10 gear 0.4802848 -0.4926866 -0.5555692 -0.1257043 0.69961013
## 11 carb -0.5509251 0.5269883 0.3949769 0.7498125 -0.09078980
## # ... with 6 more variables: wt <dbl>, qsec <dbl>, vs <dbl>, am <dbl>,
## # gear <dbl>, carb <dbl>
Die Korrelationen nach Stärke ordnen geht so:
mtcars %>%
correlate %>%
rearrange(absolute = FALSE) %>%
shave()
## # A tibble: 11 × 12
## rowname mpg vs drat am gear
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 mpg NA NA NA NA NA
## 2 vs 0.6640389 NA NA NA NA
## 3 drat 0.6811719 0.4402785 NA NA NA
## 4 am 0.5998324 0.1683451 0.71271113 NA NA
## 5 gear 0.4802848 0.2060233 0.69961013 0.79405876 NA
## 6 qsec 0.4186840 0.7445354 0.09120476 -0.22986086 -0.2126822
## 7 carb -0.5509251 -0.5696071 -0.09078980 0.05753435 0.2740728
## 8 hp -0.7761684 -0.7230967 -0.44875912 -0.24320426 -0.1257043
## 9 wt -0.8676594 -0.5549157 -0.71244065 -0.69249526 -0.5832870
## 10 disp -0.8475514 -0.7104159 -0.71021393 -0.59122704 -0.5555692
## 11 cyl -0.8521620 -0.8108118 -0.69993811 -0.52260705 -0.4926866
## # ... with 6 more variables: qsec <dbl>, carb <dbl>, hp <dbl>, wt <dbl>,
## # disp <dbl>, cyl <dbl>
Und plotten so:
mtcars %>%
correlate %>%
rearrange(absolute = FALSE) %>%
shave() %>%
rplot()
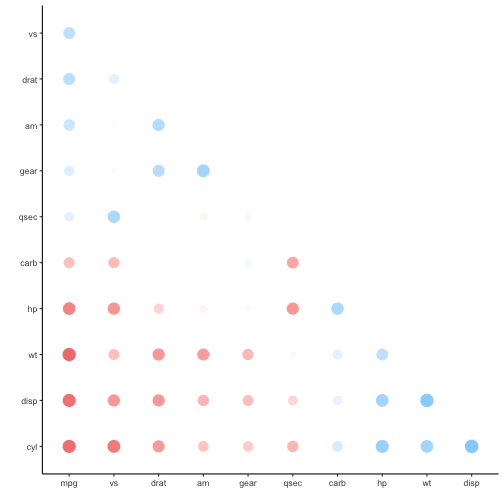
Häufigkeiten zählen - count
Wie viele Brillenträger gibt es bei den Männern bzw. den Frauen in der Stichprobe? Wie häufig gibt es Autos mit 4, 6 oder 8 Zylindern? Solche Häufigkeitsauswerteungen lassen sich z.B. mit dplyr::count erledigen.
dplyr::count(mtcars,cyl)
## # A tibble: 3 × 2
## cyl n
## <dbl> <int>
## 1 4 11
## 2 6 7
## 3 8 14
dplyr::count(mtcars,cyl, gear)
## Source: local data frame [8 x 3]
## Groups: cyl [?]
##
## cyl gear n
## <dbl> <dbl> <int>
## 1 4 3 1
## 2 4 4 8
## 3 4 5 2
## 4 6 3 2
## 5 6 4 4
## 6 6 5 1
## 7 8 3 12
## 8 8 5 2
Scatterplot-Matrix - GGally::ggpairs
Eine Scatterplot-Matrix kann helfen, den Zusammenhang zwischen mehreren Variablen zu visualisieren.
data(tips, package = "reshape2")
library(GGally)
ggpairs(tips, columns = c("tip", "sex", "total_bill"), aes(fill = sex))
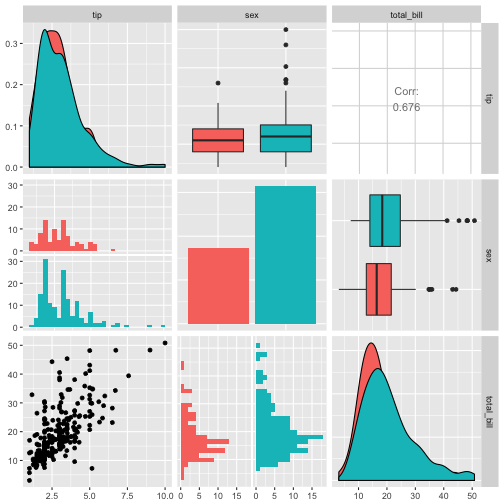
Regression (Lineares Modell) - lm
Um eine Regression zu berechnen, verwendet man meist den Befehl lm.
lm1 <- lm(tip ~ total_bill, data = tips)
summary(lm1)
##
## Call:
## lm(formula = tip ~ total_bill, data = tips)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.1982 -0.5652 -0.0974 0.4863 3.7434
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.920270 0.159735 5.761 2.53e-08 ***
## total_bill 0.105025 0.007365 14.260 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.022 on 242 degrees of freedom
## Multiple R-squared: 0.4566, Adjusted R-squared: 0.4544
## F-statistic: 203.4 on 1 and 242 DF, p-value: < 2.2e-16
Man kann als Prädiktoren auch nominale Variablen verwenden:
lm2 <- lm(tip ~ sex, data = tips)
summary(lm2)
##
## Call:
## lm(formula = tip ~ sex, data = tips)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.0896 -1.0896 -0.0896 0.6666 6.9104
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.8334 0.1481 19.137 <2e-16 ***
## sexMale 0.2562 0.1846 1.388 0.166
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.381 on 242 degrees of freedom
## Multiple R-squared: 0.007896, Adjusted R-squared: 0.003797
## F-statistic: 1.926 on 1 and 242 DF, p-value: 0.1665
In diesem Fall gleicht die Regression einem t-Test.