---
exname: variability02
extype: schoice
exsolution: 1
exshuffle: no
categories:
- variability
- basics
- schoice
date: '2023-02-02'
slug: variability02
title: variability02
---
```{r libs, include = FALSE}
library(tidyverse)
library(easystats)
```
```{r global-knitr-options, include=FALSE}
knitr::opts_chunk$set(fig.pos = 'H',
fig.asp = 0.618,
fig.width = 7,
fig.cap = "",
fig.path = "",
echo = FALSE,
out.width = "100%",
message = FALSE,
fig.show = "hold")
```
# Aufgabe
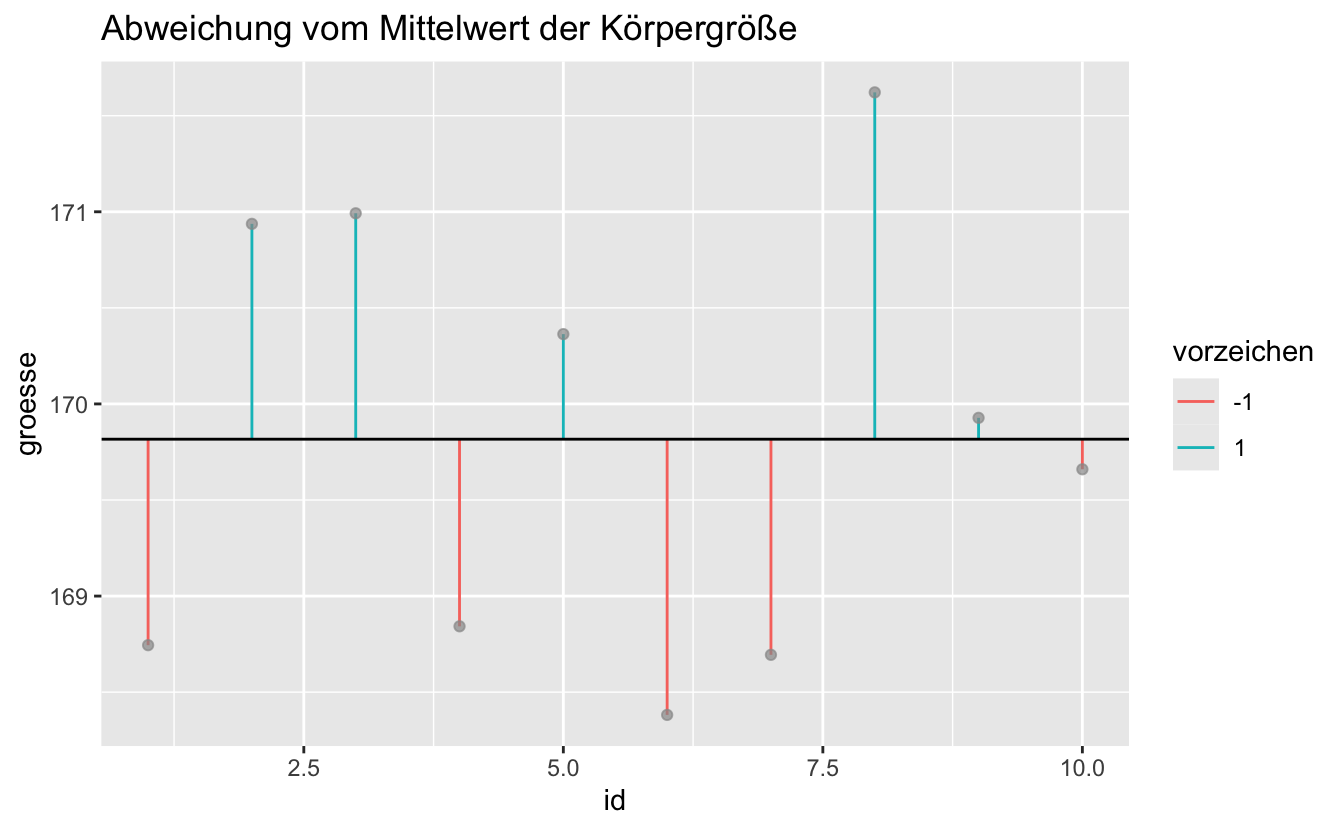
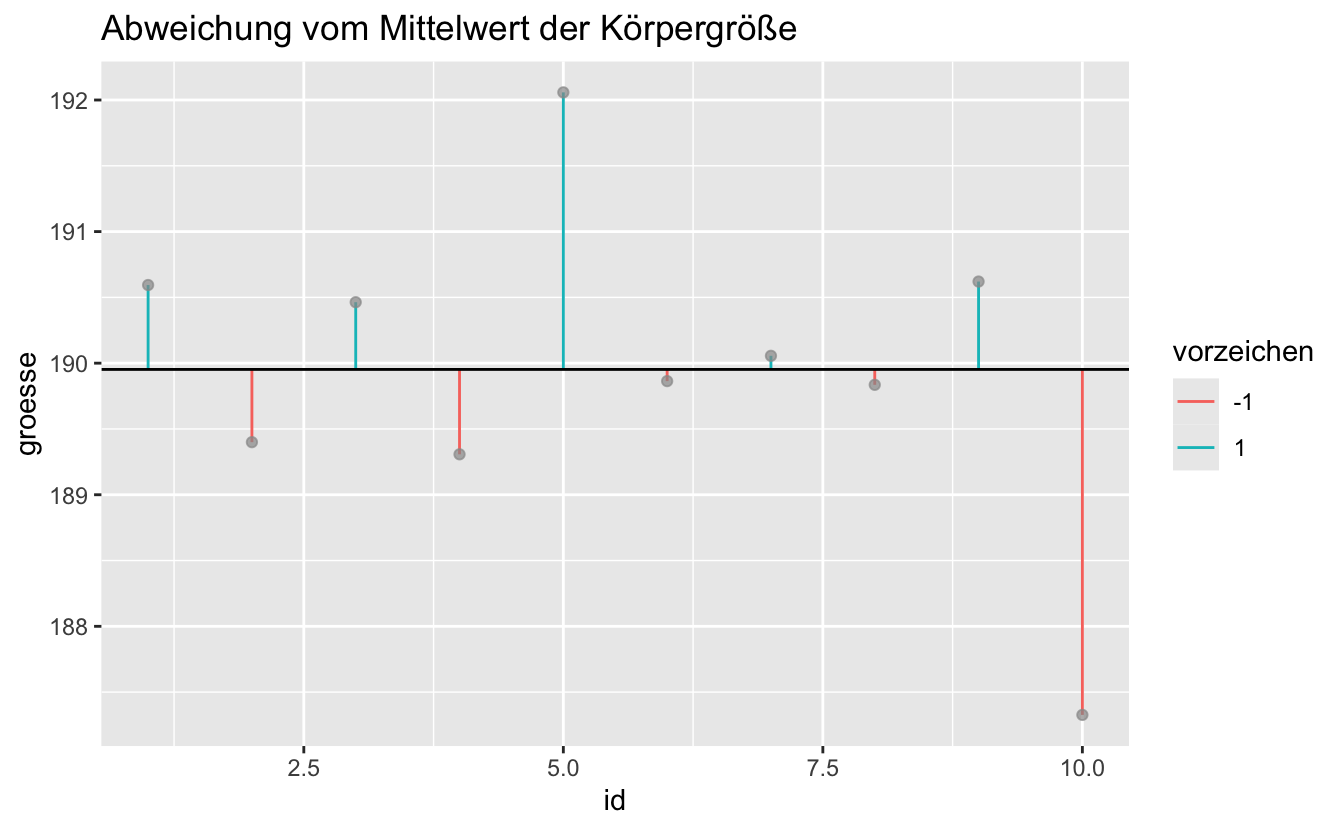
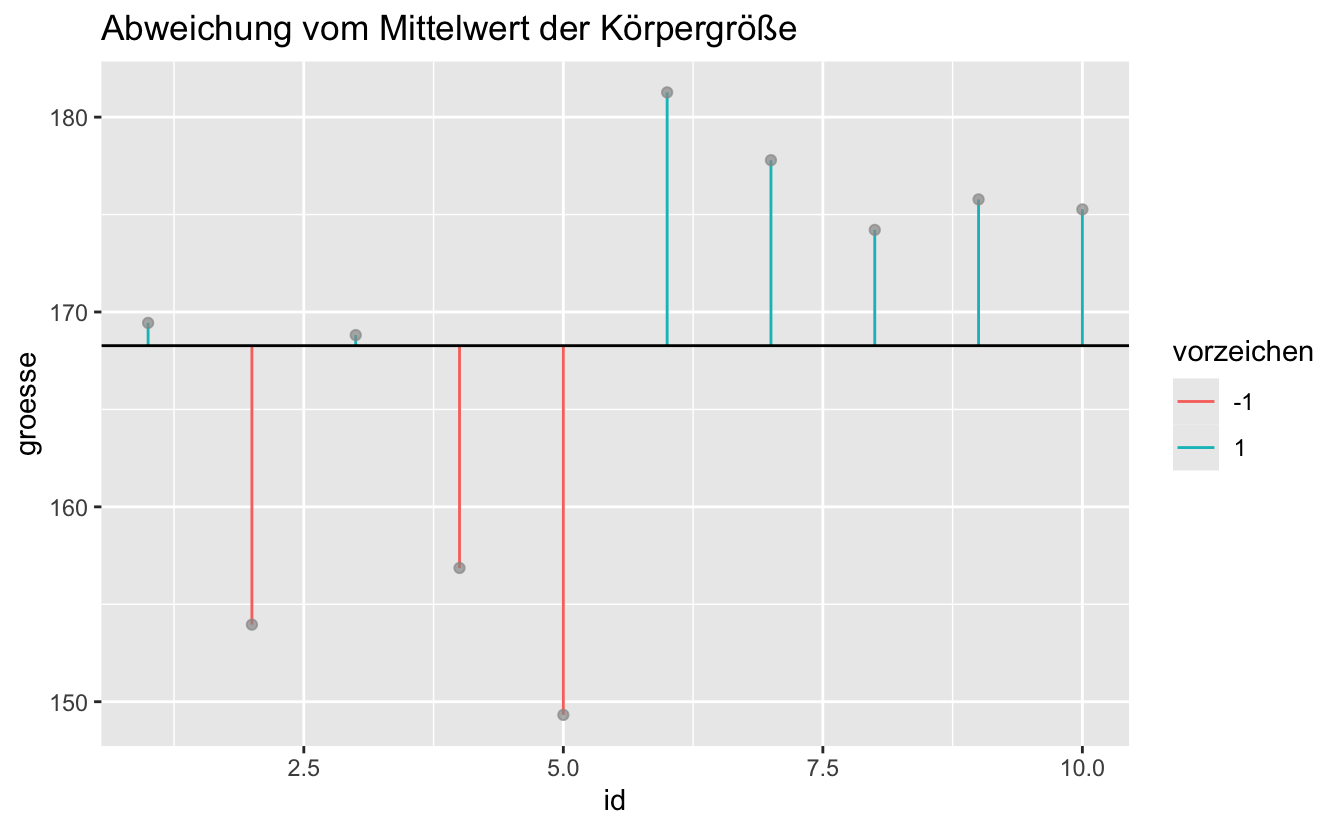
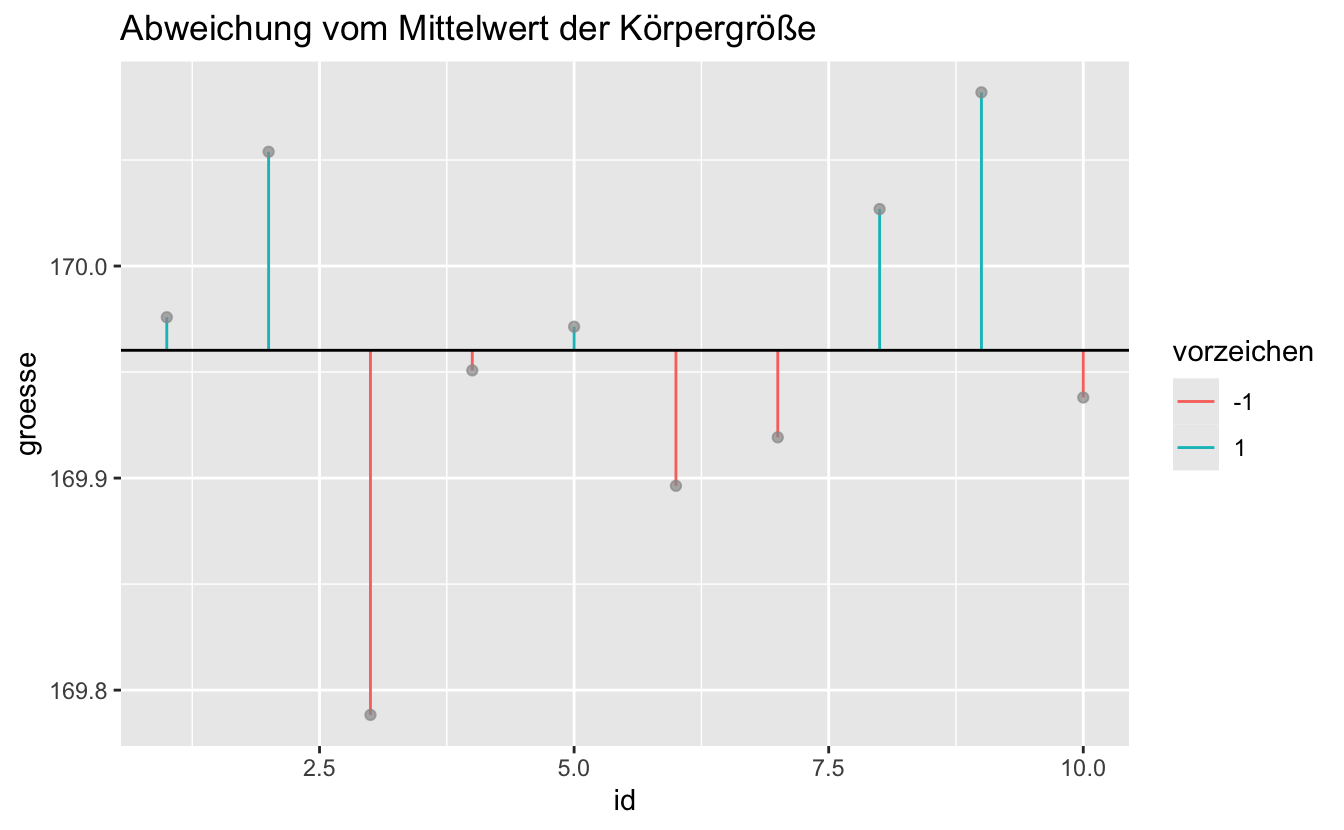
In welchem Datensatz (x1-x4) gibt es am meisten Variation?
```{r}
groesse_df <-
tibble(
x1 = 170 + rnorm(n = 10, mean = 0, sd = 1),
x2 = 190 + rnorm(n = 10, mean = 0, sd = 1),
x3 = 170 + rnorm(n = 10, mean = 0, sd = 10),
x4 = 170 + rnorm(n = 10, mean = 0, sd = 0.1),
id = 1:10
)
```
Datensatz A:
```{r}
groesse_df2 <-
groesse_df %>%
mutate(groesse = x1) %>%
mutate(groesse_mw = mean(groesse)) %>%
mutate(abweichung = groesse - groesse_mw) %>%
mutate(vorzeichen = factor(sign(abweichung)))
groesse_df2 %>%
ggplot(aes(x = id)) +
geom_segment(aes(xend = id, y = groesse, yend = groesse_mw, color = vorzeichen)) +
geom_point(aes(x = id, y = groesse), color = "grey60", alpha = .7) +
geom_hline(aes(yintercept = groesse_mw)) +
labs(title = "Abweichung vom Mittelwert der Körpergröße")
```
Datensatz B:
```{r}
groesse_df2 <-
groesse_df %>%
mutate(groesse = x2) %>%
mutate(groesse_mw = mean(groesse)) %>%
mutate(abweichung = groesse - groesse_mw) %>%
mutate(vorzeichen = factor(sign(abweichung)))
groesse_df2 %>%
ggplot(aes(x = id)) +
geom_segment(aes(xend = id, y = groesse, yend = groesse_mw, color = vorzeichen)) +
geom_point(aes(x = id, y = groesse), color = "grey60", alpha = .7) +
geom_hline(aes(yintercept = groesse_mw)) +
labs(title = "Abweichung vom Mittelwert der Körpergröße")
```
Datensatz C:
```{r}
groesse_df2 <-
groesse_df %>%
mutate(groesse = x3) %>%
mutate(groesse_mw = mean(groesse)) %>%
mutate(abweichung = groesse - groesse_mw) %>%
mutate(vorzeichen = factor(sign(abweichung)))
groesse_df2 %>%
ggplot(aes(x = id)) +
geom_segment(aes(xend = id, y = groesse, yend = groesse_mw, color = vorzeichen)) +
geom_point(aes(x = id, y = groesse), color = "grey60", alpha = .7) +
geom_hline(aes(yintercept = groesse_mw)) +
labs(title = "Abweichung vom Mittelwert der Körpergröße")
```
Datensatz D:
```{r}
groesse_df2 <-
groesse_df %>%
mutate(groesse = x4) %>%
mutate(groesse_mw = mean(groesse)) %>%
mutate(abweichung = groesse - groesse_mw) %>%
mutate(vorzeichen = factor(sign(abweichung)))
groesse_df2 %>%
ggplot(aes(x = id)) +
geom_segment(aes(xend = id, y = groesse, yend = groesse_mw, color = vorzeichen)) +
geom_point(aes(x = id, y = groesse), color = "grey60", alpha = .7) +
geom_hline(aes(yintercept = groesse_mw)) +
labs(title = "Abweichung vom Mittelwert der Körpergröße")
```
Answerlist
----------
* A
* B
* C
* D
</br>
</br>
</br>
</br>
</br>
</br>
</br>
</br>
</br>
</br>
# Lösung
Hier ist die Streuung (SD) für die vier Datensätze (x1 bis x4):
```{r}
groesse_df2 |>
summarise(across(x1:x4, sd))
```
Answerlist
----------
* Falsch
* Falsch
* Falsch
* Wahr
---
Categories:
- variablity
- basics
- schoice