library(tidyverse)nasa01
data
eda
lagemaße
variability
string
Aufgabe
Viele Quellen berichten Klimadaten unserer Erde, z.B. auch National Aeronautics and Space Administration - Goddard Institute for Space Studies.
Von dieser Quelle beziehen wir diesen Datensatz.
Die Datensatz sind auf der Webseite wie folgt beschrieben:
Tables of Global and Hemispheric Monthly Means and Zonal Annual Means
Combined Land-Surface Air and Sea-Surface Water Temperature Anomalies (Land-Ocean Temperature Index, L-OTI)
The following are plain-text files in tabular format of temperature anomalies, i.e. deviations from the corresponding 1951-1980 means.
Global-mean monthly, seasonal, and annual means, 1880-present, updated through most recent month: TXT, CSV
Starten Sie zunächst das R-Paket tidyverse falls noch nicht geschehen.
Importieren Sie dann die Daten:
data_path <- "https://data.giss.nasa.gov/gistemp/tabledata_v4/GLB.Ts+dSST.csv"
d <- read.csv(data_path, skip = 1)Wir lassen die 1. Zeile des Datensatzes aus (Argument skip), da dort Metadaten stehen, also keine Daten, sondern Informationen (Daten) zu den eigentlichen Daten.
Aufgabe
Berechnen und visualisieren Sie die folgende Statistiken pro Dekade:
Mittelwert der Temperatur im Januar
SD der Temperatur im Januar
Hinweise:
- Sie müssen zuerst die Dekade als neue Spalte berechnen.
Lösung
Setup
library(ggpubr)
library(DataExplorer)Daten aufbereiten
Dekade berechnen:
d <-
d %>%
mutate(decade = round(Year/10))Das ist ein möglicher Weg, um aus einer Jahreszahl die Dekade zu berechnen.
Statistiken berechnen
Statistiken pro Dekade:
d_summarized <-
d %>%
group_by(decade) %>%
summarise(temp_mean = mean(Jan),
temp_sd = sd(Jan))
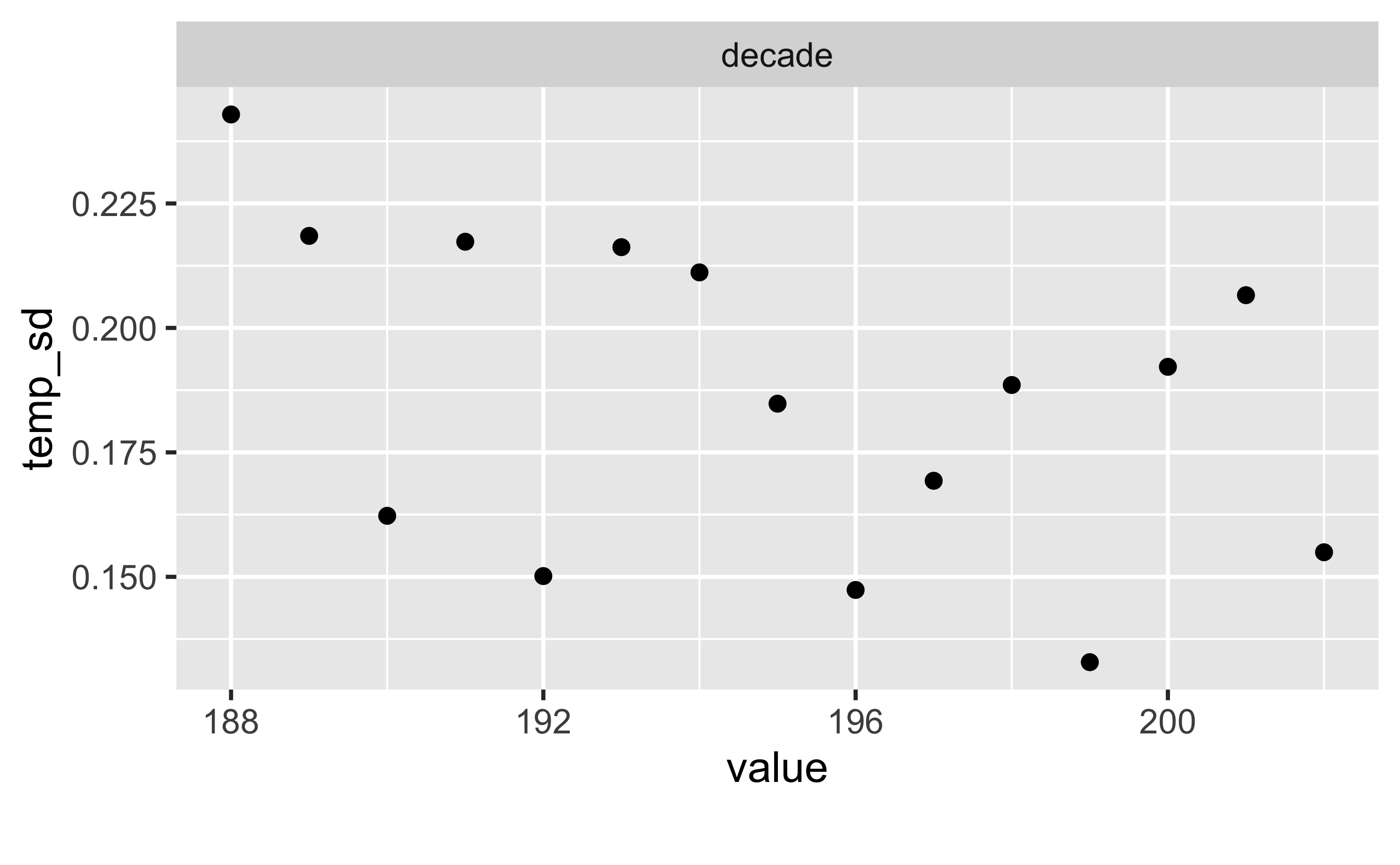
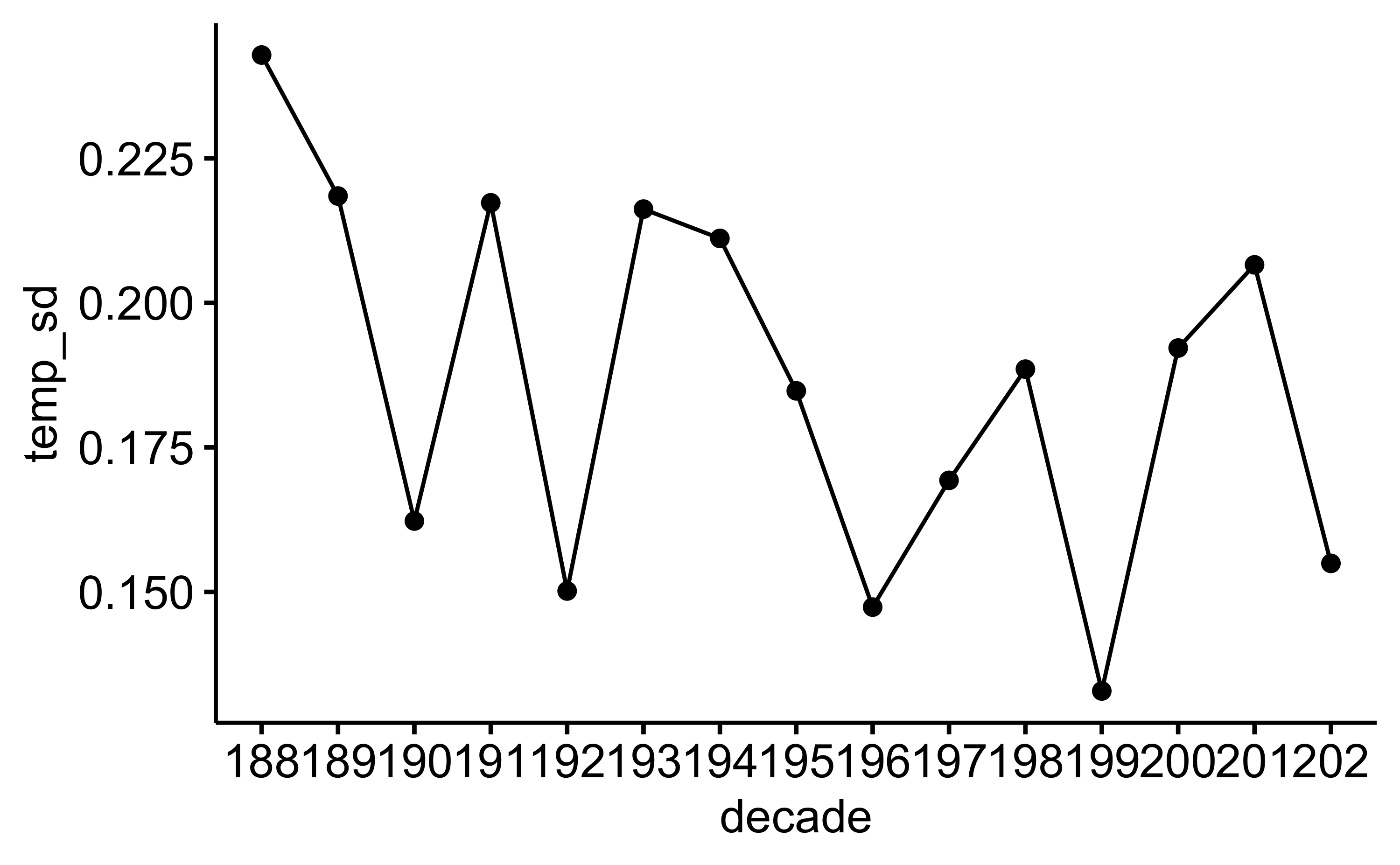
d_summarized| decade | temp_mean | temp_sd |
|---|---|---|
| 188 | −0.21 | 0.24 |
| 189 | −0.45 | 0.22 |
| 190 | −0.27 | 0.16 |
| 191 | −0.40 | 0.22 |
| 192 | −0.29 | 0.15 |
| 193 | −0.14 | 0.21 |
| 194 | 0.02 | 0.22 |
| 195 | −0.05 | 0.19 |
| 196 | 0.03 | 0.15 |
| 197 | −0.07 | 0.17 |
| 198 | 0.21 | 0.19 |
| 199 | 0.35 | 0.13 |
| 200 | 0.51 | 0.19 |
| 201 | 0.63 | 0.21 |
| 202 | 1.02 | 0.19 |
Statistiken visualisieren
Mit DataExplorer
d_summarized |>
select(decade, temp_mean) |>
plot_scatterplot(by = "temp_mean")
d_summarized |>
select(decade, temp_sd) |>
plot_scatterplot(by = "temp_sd")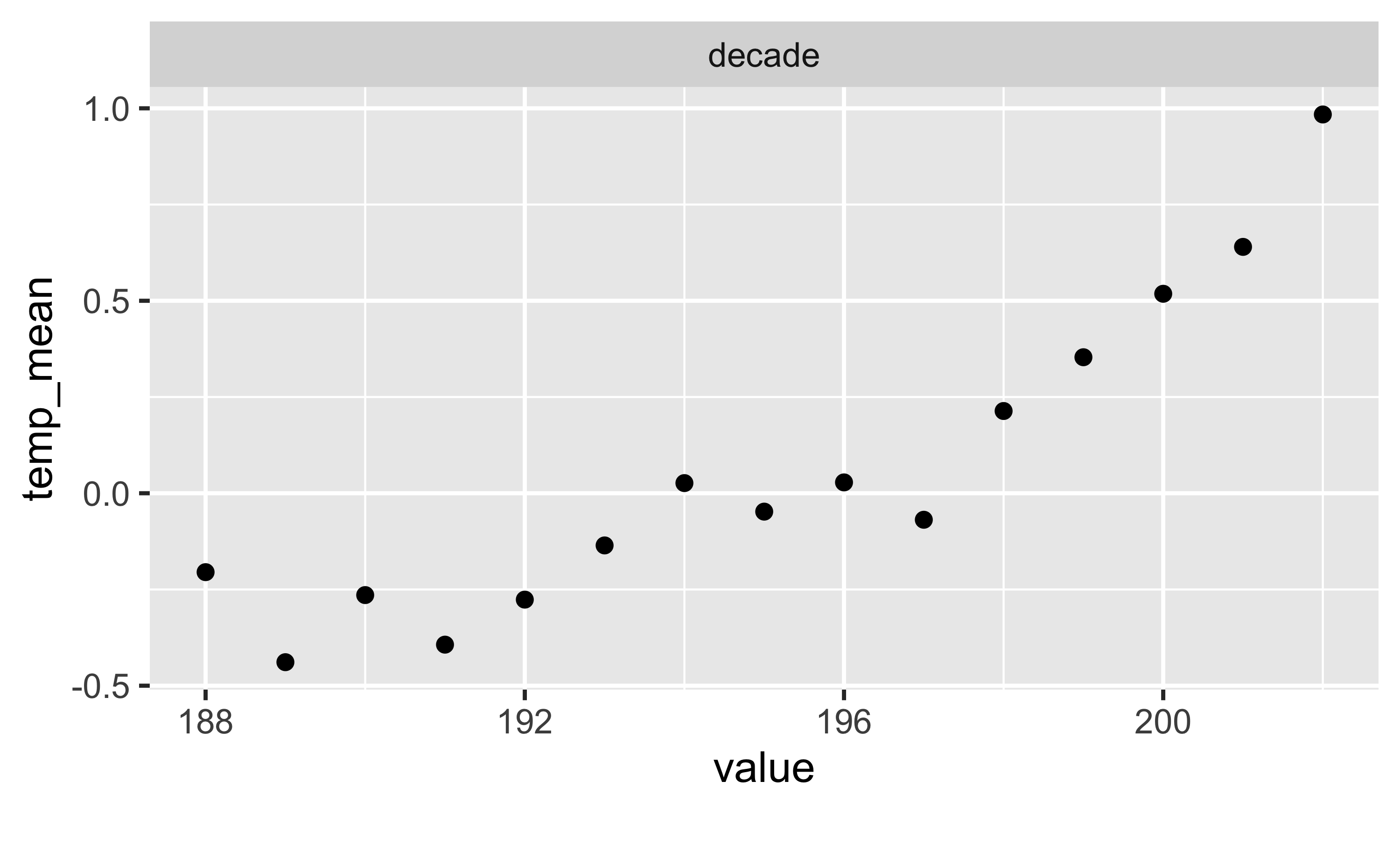
Mit ggpubr
d_summarized |>
ggline(x = "decade", y = "temp_mean")
d_summarized |>
ggline(x = "decade", y = "temp_sd")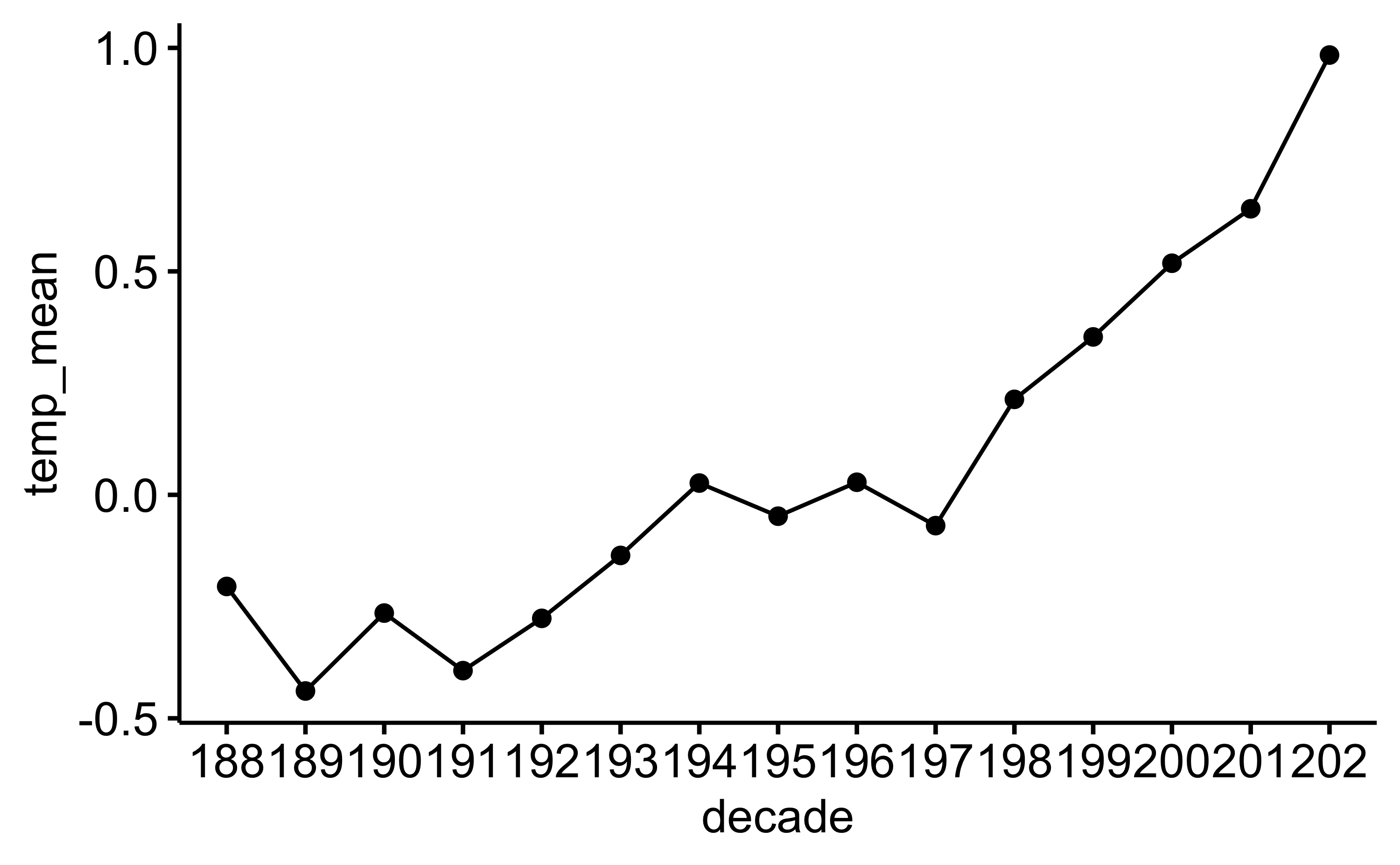
d |>
ggerrorplot(x = "decade", y = "Jan")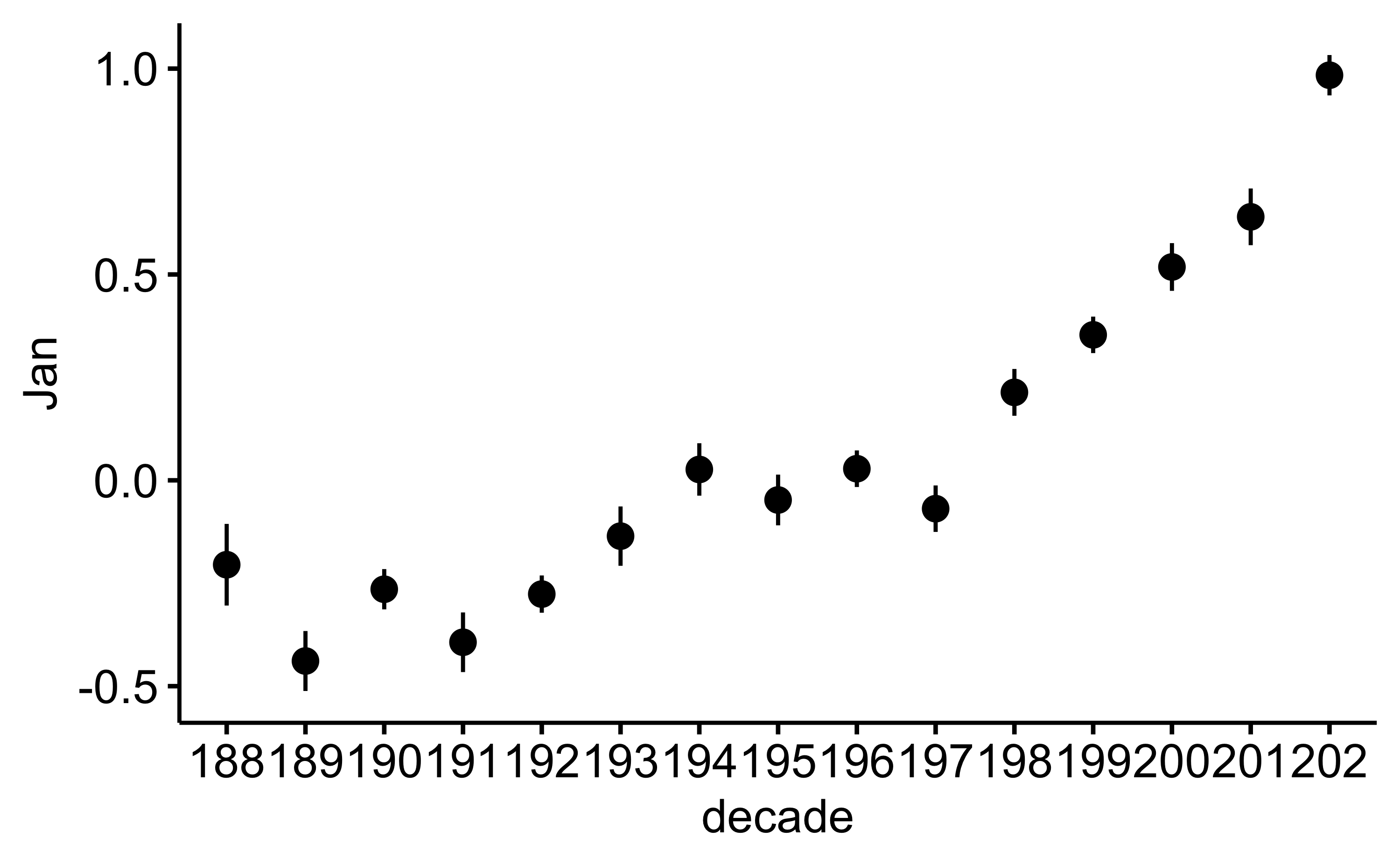
Falls Sie Teile der R-Syntax nicht kennen: Machen Sie sich nichts daraus. 😄
Categories:
- data
- eda
- lagemaße
- variability
- string