data(mtcars) # mtcars importieren
mtcars %>%
select(mpg, hp) %>%
slice_head(n = 5)| mpg | hp | |
|---|---|---|
| Mazda RX4 | 21.0 | 110 |
| Mazda RX4 Wag | 21.0 | 110 |
| Datsun 710 | 22.8 | 93 |
| Hornet 4 Drive | 21.4 | 110 |
| Hornet Sportabout | 18.7 | 175 |
Im Folgenden ist der Datensatz mtcars zu analysieren.
Der Datensatz ist z.B. als CSV-Datei von dieser Webseite abrufbar.
Hilfe zum Datensatz ist via dieser Webseite abrufbar.
Ob die Variable hp (UV) und Spritverbrauch (mpg; AV) wohl voneinander abhängig sind? Was meinen Sie? Was ist Ihre Einschätzung dazu? Vermutlich haben Sie ein (wenn vielleicht auch implizites) Vorab-Wissen zu dieser Frage. Lassen wir dieses Vorab-Wissen aber einmal außen vor und schauen uns rein Daten dazu an. Vereinfachen wir die Frage etwas, indem wir beide Variablen am Mittelwert aufteilen: Wenn eine Beobachtung (d.h. ein Auto) einen Wert in der jeweiligen Variablen höchstens so groß wie der Mittelwert der Variable aufweist, geben wir der Beobachtung der Wert 0, ansonsten den Wert 1. Das Ereignis \(A\) sei “hoher Spritverbrauch”, mpg_high == 1. Das Ereignis \(B\) sei “hohe PS_Zahl”, hp_high == 1.
Berechnen Sie: \(Pr(\neg \text{uv high} \, | \, \text{av high})\)
Hinweise:
Dieser Prädiktor wurde als UV bestimmt: hp.
Schauen wir zuerst mal in den Datensatz:
data(mtcars) # mtcars importieren
mtcars %>%
select(mpg, hp) %>%
slice_head(n = 5)| mpg | hp | |
|---|---|---|
| Mazda RX4 | 21.0 | 110 |
| Mazda RX4 Wag | 21.0 | 110 |
| Datsun 710 | 22.8 | 93 |
| Hornet 4 Drive | 21.4 | 110 |
| Hornet Sportabout | 18.7 | 175 |
Dann berechnen wir die binären Variablen:
mtcars2 <-
mtcars %>%
select(mpg, hp) %>%
mutate(mpg_high = case_when(
mpg <= mean(mpg) ~ 0,
mpg > mean(mpg) ~ 1
)) %>%
select(-mpg)
mtcars3 <- # Jetzt analog für die UV, `hp`:
mtcars2 |>
mutate(hp_high = case_when(
hp <= mean(hp) ~ 0,
hp > mean(hp) ~ 1
)) |>
select(-hp)Dann filtern wir die gesuchten Wahrscheinlichkeiten bzw. Anteile der AV:
mtcars3_filtered <-
mtcars3 %>%
filter(mpg_high == 1)
mtcars3_filtered| mpg_high | hp_high | |
|---|---|---|
| Mazda RX4 | 1 | 0 |
| Mazda RX4 Wag | 1 | 0 |
| Datsun 710 | 1 | 0 |
| Hornet 4 Drive | 1 | 0 |
| Merc 240D | 1 | 0 |
| Merc 230 | 1 | 0 |
| Fiat 128 | 1 | 0 |
| Honda Civic | 1 | 0 |
| Toyota Corolla | 1 | 0 |
| Toyota Corona | 1 | 0 |
| Fiat X1-9 | 1 | 0 |
| Porsche 914-2 | 1 | 0 |
| Lotus Europa | 1 | 0 |
| Volvo 142E | 1 | 0 |
Die Anzahl der Zeilen in mtcars3_filtered sagt uns, wie viele Autos die gesuchte Bedingung, also den “hinteren Teil” der Wahrscheinlichkeit, erfüllen.
Zur Erinnerung: Bedingte Wahrscheinlichkeit berechnen ist analog zum Filtern einer Tabelle:
Es gibt also 14 Autos, die den oben gesuchten “hinteren Teil” der Bedingung erfüllen (mpg_high = 1).
Filtern wir als nächstes nach dem “vorderen Teil” der gesuchten Wahrscheinlichkeit (was das gleiche ist wie ein Anteil in diesem Fall):
mtcars3_filtered %>%
filter(hp_high == 0) | mpg_high | hp_high | |
|---|---|---|
| Mazda RX4 | 1 | 0 |
| Mazda RX4 Wag | 1 | 0 |
| Datsun 710 | 1 | 0 |
| Hornet 4 Drive | 1 | 0 |
| Merc 240D | 1 | 0 |
| Merc 230 | 1 | 0 |
| Fiat 128 | 1 | 0 |
| Honda Civic | 1 | 0 |
| Toyota Corolla | 1 | 0 |
| Toyota Corona | 1 | 0 |
| Fiat X1-9 | 1 | 0 |
| Porsche 914-2 | 1 | 0 |
| Lotus Europa | 1 | 0 |
| Volvo 142E | 1 | 0 |
Es gibt also 14 Autos, für die gilt hp_high == 0.
Mit count kann man sich die Werte zählen lassen:
| hp_high | n |
|---|---|
| 0 | 14 |
Der gesuchte Wert beträgt also 14/14 = 1.
Visualisieren wir noch die bedingten Wahrscheinlichkeiten, so könnte man die gesuchten Anteile einfach abzählen:
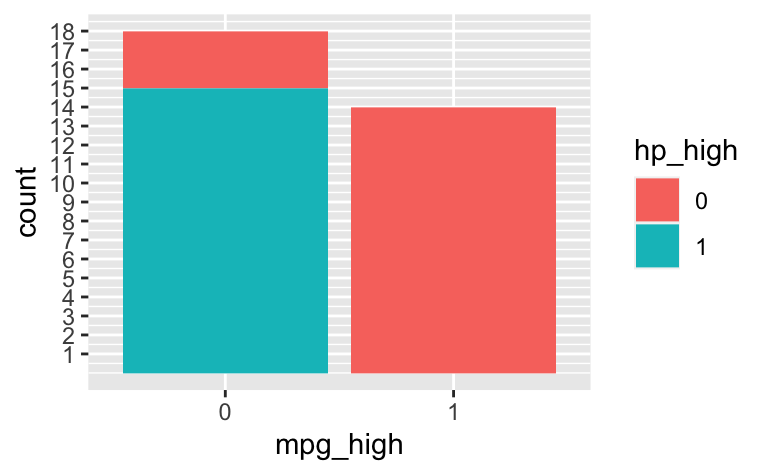
Sieht man in dem Diagramm nur eine Farbe (anstelle von zweien), so heißt das, dass es nur eine Gruppe gibt (und nicht zwei). Die Häufigkeit der nicht vorhandenen Gruppe ist demnach Null.
Categories: