library(tidyverse)
library(DataExplorer)movies-vis1
vis
eda
string
Aufgabe
Importieren Sie bitte für diese Aufgabe den Datensatz movies (aus dem R-Paket ggplot2movies). Ein Data-Dictionary findet sich hier.
Erstellen Sie folgende Visualisierung:
- Streudiagramme mit
ratingals Y-Variable, und alle übrigen metrischen Variablen als X-Variable. - Lassen Sie aber folgende Variablen außen vor: etwaige ID-Variablen, die Variablen, die die Perzentile der Bewertungen angeben (
rX, mitXvon 1 bis 10) - Berücksichtigen Sie nur Actionfilme ab 2000
- Verzichten Sie auf Filme mit einer unterdurchschnittlichen Zahl an Bewertungen (
votes; gemessen an allen Filmen, gerundet zur nächsten ganzen Zahl)
Lösung
Pakete starten:
Daten importieren:
d_path <- "https://vincentarelbundock.github.io/Rdatasets/csv/ggplot2movies/movies.csv"
d <- read.csv(d_path)Durchschnittliche Zahl an Bewertungen:
d %>%
summarise(votes_mean = mean(votes))| votes_mean |
|---|
| 632.1304 |
Die durchschnittliche Zahl an Bewertungen beträgt also 632.
d %>%
select(length, budget, rating, year, votes, Action) %>%
filter(year >= 2000) %>%
filter(Action == 1) %>%
filter(votes >= 632) %>%
select(-Action) %>%
plot_scatterplot(by = "rating")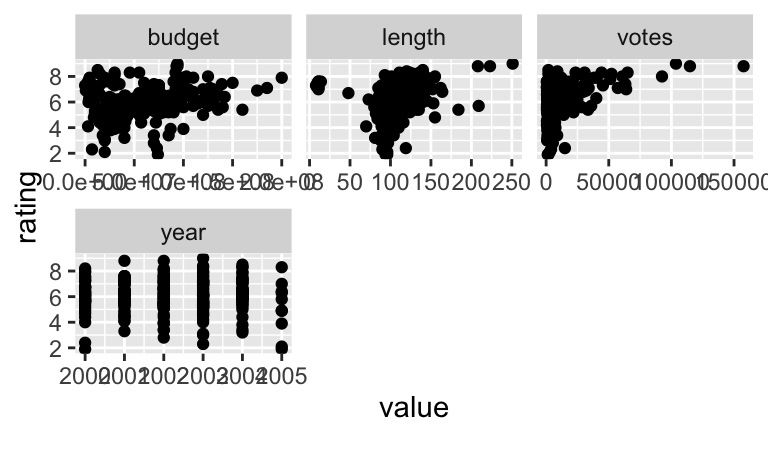
Categories:
- vis
- eda
- string