library(tidytext)
library(tidyverse)
d <- read_csv(path_to_data)
stopwords <- get_stopwords()
emo <- get_sentiments('nrc')
wordcount_plot1 <-
d %>%
select(review) %>%
unnest_tokens(word, review) %>%
filter(str_detect(word, "[a-z']+")) %>%
anti_join(stopwords) %>%
inner_join(emo) %>%
count(word, sort = TRUE) %>%
slice_head(n = 10) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(n, word)) +
geom_col()movie-sentiment1
textmining
imdb
schoice
Aufgabe
Eine typische Aufgabe des Textminings ist die Sentimentanalyse. Betrachten wir dazu einen Datensatz des Filmbewertungsportal IMDB. Das Portal veröffentlicht Bewertungen (quantitativ und qualitativ, d.h. als Score oder Bewertung/Review) zu Filmen der Nutzerinnen und Nutzer. Der Datensatz kann über Kaggle bezogen werden.
Im Rahmen einer Fallstudie soll eine Sentimentanalyse wie folgt abgearbeitet werden:
- Daten in R importieren
- Relevante Spalten auswählen (die die Reviews der Nutzer enthalten)
- Daten in das “Tidytext-Format” überführen
- Nicht-Wörter (z.B. Zahlen) entfernen
- Stopwörter entfernen
- Sentimentanalyse durchführen zur Identifikation der Grundemotionen
- Visualisierung der Intensität der Emotionen der 10 häufigsten Wörter (sortierte Balken)
Hinweise:
- Hier ist nur ein Teil des Datensatzes dargestellt (aus Gründen der Einfachheit).
- Gehen Sie davon aus, dass die Daten unter dem Pfad verfügbar sind, der in dieser Variable gespeichert ist:
path_to_data. Die relevanten Spalten sind dort schon ausgewählt.
Welcher der folgenden R-Syntaxen führt diese Analyse korrekt aus? Wählen Sie die am besten passende Antwort!
library(tidytext)
library(tidyverse)
d <- read_csv(path_to_data)
stopwords <- get_stopwords()
emo <- get_sentiments('afinn')
d %>%
select(review) %>%
unnest_tokens(output = word, input = review) %>%
filter(str_detect(word, "[a-z']+")) %>%
left_join(stopwords) %>%
inner_join(emo) %>%
count(word, sort=TRUE) %>%
slice_head(n = 10) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(x = n, y = word)) +
geom_col()library(tidytext)
library(tidyverse)
d <- read_csv(path_to_data)
stopwords <- get_stopwords()
emo <- get_sentiments('bing')
d %>%
select(review) %>%
unnest_tokens(word, review) %>%
filter(str_detect(word, "[a-z']+")) %>%
anti_join(stopwords) %>%
left_join(emo) %>%
count(word, sort = TRUE) %>%
slice_head(n = 10) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(n, word)) +
geom_col()library(tidytext)
library(tidyverse)
d <- read_csv(path_to_data)
stopwords <- get_stopwords()
emo <- get_sentiments('loughran')
d %>%
select(review) %>%
unnest_tokens(word, review) %>%
filter(str_detect(word, '\\w.')) %>%
anti_join(stopwords) %>%
inner_join(emo) %>%
count(word, sort = TRUE) %>%
slice_head(n = 10) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(n, word)) +
geom_col()library(tidytext)
library(tidyverse)
d <- read_csv(path_to_data)
stopwords <- get_stopwords()
emo <- get_sentiments()
d %>%
select(review) %>%
unnest_tokens(word, review) %>%
filter(str_detect(word, "[a-z']+")) %>%
anti_join(stopwords) %>%
inner_join(emo) %>%
count(word) %>%
slice_head(n = 10) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(n, word)) +
geom_bar()library(tidyverse)
library(tidytext)
d <- read_csv(path_to_data)
emo <- get_sentiments()
stopwords <- get_stopwords()
d %>%
select(review) %>%
unnest_tokens(input = word, output = review) %>%
filter(str_detect(word, "[a-z']+")) %>%
anti_join(stopwords) %>%
inner_join(emos) %>%
count(word) %>%
slice_head(n = 10) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot() +
aes(n, word) +
geom_bar()library(tidytext)
library(tidyverse)
d <- read_csv(path_to_data)
stopwords <- get_stopwords()
emo <- get_sentiments('nrc')
d %>%
select(review) %>%
unnest_tokens(word, review) %>%
filter(str_detect(word, "[a-z']+")) %>%
left_join(stopwords) %>%
inner_join(emo) %>%
count(word, sort = TRUE) %>%
slice(n = 10) %>%
ggplot(aes(x = n, y = word)) +
geom_bar()library(tidytext)
library(tidyverse)
d <- read_csv(path_to_data)
stopwords <- get_stopwords()
emo <- get_sentiments('nrc')
d %>%
select(review) %>%
unnest_tokens(word, review) %>%
filter(str_detect(word, '\\w.')) %>%
anti_join(stopwords) %>%
inner_join(emo) %>%
count(word) %>%
slice_head(n = 10) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(n, word)) %>%
geom_col()syntax1 <-
"
library(tidytext)
library(tidyverse)
d <- read_csv(path_to_data)
stopwords <- get_stopwords()
emo <- get_sentiments('nrc')
wordcount_plot1 <-
d %>%
select(review) %>%
unnest_tokens(word, review) %>%
filter(str_detect(word, '[a-z]+')) %>%
anti_join(stopwords) %>%
inner_join(emo) %>%
count(word, sort = TRUE) %>%
slice_head(n = 10) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(n, word)) +
geom_col()
"syntax2 <-
"
library(tidytext)
library(tidyverse)
d <- read_csv(path_to_data)
stopwords <- get_stopwords()
emo <- get_sentiments('afinn')
wordcount_plot1 <-
d %>%
select(review) %>%
unnest_tokens(output = word, input = review) %>%
filter(str_detect(word, '[a-z]+')) %>%
left_join(stopwords) %>%
inner_join(emo) %>%
count(word, sort=TRUE) %>%
slice_head(n = 10) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(x = n, y = word)) +
geom_col()
"syntax3 <-
"
library(tidytext)
library(tidyverse)
d <- read_csv(path_to_data)
stopwords <- get_stopwords()
emo <- get_sentiments('bing')
wordcount_plot1 <-
d %>%
select(review) %>%
unnest_tokens(word, review) %>%
filter(str_detect(word, '[a-z]+')) %>%
anti_join(stopwords) %>%
left_join(emo) %>%
count(word, sort = TRUE) %>%
slice_head(n = 10) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(n, word)) +
geom_col()
"syntax4 <-
"
library(tidytext)
library(tidyverse)
d <- read_csv(path_to_data)
stopwords <- get_stopwords()
emo <- get_sentiments('loughran')
wordcount_plot1 <-
d %>%
select(review) %>%
unnest_tokens(word, review) %>%
filter(str_detect(word, '\\w.')) %>%
anti_join(stopwords) %>%
inner_join(emo) %>%
count(word, sort = TRUE) %>%
slice_head(n = 10) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(n, word)) +
geom_col()
"syntax5 <-
"
library(tidytext)
library(tidyverse)
d <- read_csv(path_to_data)
stopwords <- get_stopwords()
emo <- get_sentiments()
d %>%
select(review) %>%
unnest_tokens(word, review) %>%
filter(str_detect(word, '[a-z]+')) %>%
anti_join(stopwords) %>%
inner_join(emo) %>%
count(word) %>%
slice_head(n = 10) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(n, word)) +
geom_bar()
"syntax6 <-
"
library(tidyverse)
library(tidytext)
d <- read_csv(path_to_data)
emo <- get_sentiments()
stopwords <- get_stopwords()
d %>%
select(review) %>%
unnest_tokens(input = word, output = review) %>%
filter(str_detect(word, '\\w.')) %>%
anti_join(stopwords) %>%
inner_join(emos) %>%
count(word) %>%
slice_head(n = 10) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot() +
aes(n, word) +
geom_bar()
"syntax7 <-
"
library(tidytext)
library(tidyverse)
d <- read_csv(path_to_data)
stopwords <- get_stopwords()
emo <- get_sentiments('nrc')
wordcount_plot1 <-
d %>%
select(review) %>%
unnest_tokens(word, review) %>%
filter(str_detect(word, '[a-z]+')) %>%
left_join(stopwords) %>%
inner_join(emo) %>%
count(word, sort = TRUE) %>%
slice(n = 10) %>%
ggplot(aes(x = n, y = word)) +
geom_bar()
"syntax8 <-
"
library(tidytext)
library(tidyverse)
d <- read_csv(path_to_data)
stopwords <- get_stopwords()
emo <- get_sentiments('nrc')
d %>%
select(review) %>%
unnest_tokens(word, review) %>%
filter(str_detect(word, '[a-z]+')) %>%
anti_join(stopwords) %>%
inner_join(emo) %>%
count(word) %>%
slice_head(n = 10) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(n, word)) %>%
geom_col()
"syntax_v <-
c(
syntax1,
syntax2,
syntax3,
syntax4,
syntax5,
syntax6,
syntax7,
syntax8
)
syntax_wrong <-
sample(syntax_v[2:7], 3)
syntax_chosen_df <-
tibble(syntax_chosen = c(syntax1, syntax_wrong, "keine der genannten"),
correct = c(T, F, F, F, F)) %>%
sample_n(5) %>%
mutate(nr = paste0("Syntax ", LETTERS[1:5]))Option A
cat(syntax_chosen_df$syntax_chosen[1])
library(tidytext)
library(tidyverse)
d <- read_csv(path_to_data)
stopwords <- get_stopwords()
emo <- get_sentiments()
d %>%
select(review) %>%
unnest_tokens(word, review) %>%
filter(str_detect(word, '[a-z]+')) %>%
anti_join(stopwords) %>%
inner_join(emo) %>%
count(word) %>%
slice_head(n = 10) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(n, word)) +
geom_bar()Option B
cat(syntax_chosen_df$syntax_chosen[2])
library(tidytext)
library(tidyverse)
d <- read_csv(path_to_data)
stopwords <- get_stopwords()
emo <- get_sentiments('afinn')
wordcount_plot1 <-
d %>%
select(review) %>%
unnest_tokens(output = word, input = review) %>%
filter(str_detect(word, '[a-z]+')) %>%
left_join(stopwords) %>%
inner_join(emo) %>%
count(word, sort=TRUE) %>%
slice_head(n = 10) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(x = n, y = word)) +
geom_col()Option C
cat(syntax_chosen_df$syntax_chosen[3])
library(tidytext)
library(tidyverse)
d <- read_csv(path_to_data)
stopwords <- get_stopwords()
emo <- get_sentiments('nrc')
wordcount_plot1 <-
d %>%
select(review) %>%
unnest_tokens(word, review) %>%
filter(str_detect(word, '[a-z]+')) %>%
anti_join(stopwords) %>%
inner_join(emo) %>%
count(word, sort = TRUE) %>%
slice_head(n = 10) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(n, word)) +
geom_col()Option D
cat(syntax_chosen_df$syntax_chosen[4])keine der genanntenOption E
cat(syntax_chosen_df$syntax_chosen[5])
library(tidytext)
library(tidyverse)
d <- read_csv(path_to_data)
stopwords <- get_stopwords()
emo <- get_sentiments('loughran')
wordcount_plot1 <-
d %>%
select(review) %>%
unnest_tokens(word, review) %>%
filter(str_detect(word, '\w.')) %>%
anti_join(stopwords) %>%
inner_join(emo) %>%
count(word, sort = TRUE) %>%
slice_head(n = 10) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(n, word)) +
geom_col()Answerlist
- Syntax A
- Syntax B
- Syntax C
- Syntax D
- Syntax E
Lösung
Die richtige Syntax lautet Syntax C.
cat(syntax_chosen_df$syntax_chosen[syntax_chosen_df$correct == TRUE])
library(tidytext)
library(tidyverse)
d <- read_csv(path_to_data)
stopwords <- get_stopwords()
emo <- get_sentiments('nrc')
wordcount_plot1 <-
d %>%
select(review) %>%
unnest_tokens(word, review) %>%
filter(str_detect(word, '[a-z]+')) %>%
anti_join(stopwords) %>%
inner_join(emo) %>%
count(word, sort = TRUE) %>%
slice_head(n = 10) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(n, word)) +
geom_col()Das Diagramm sieht dann so aus:
wordcount_plot1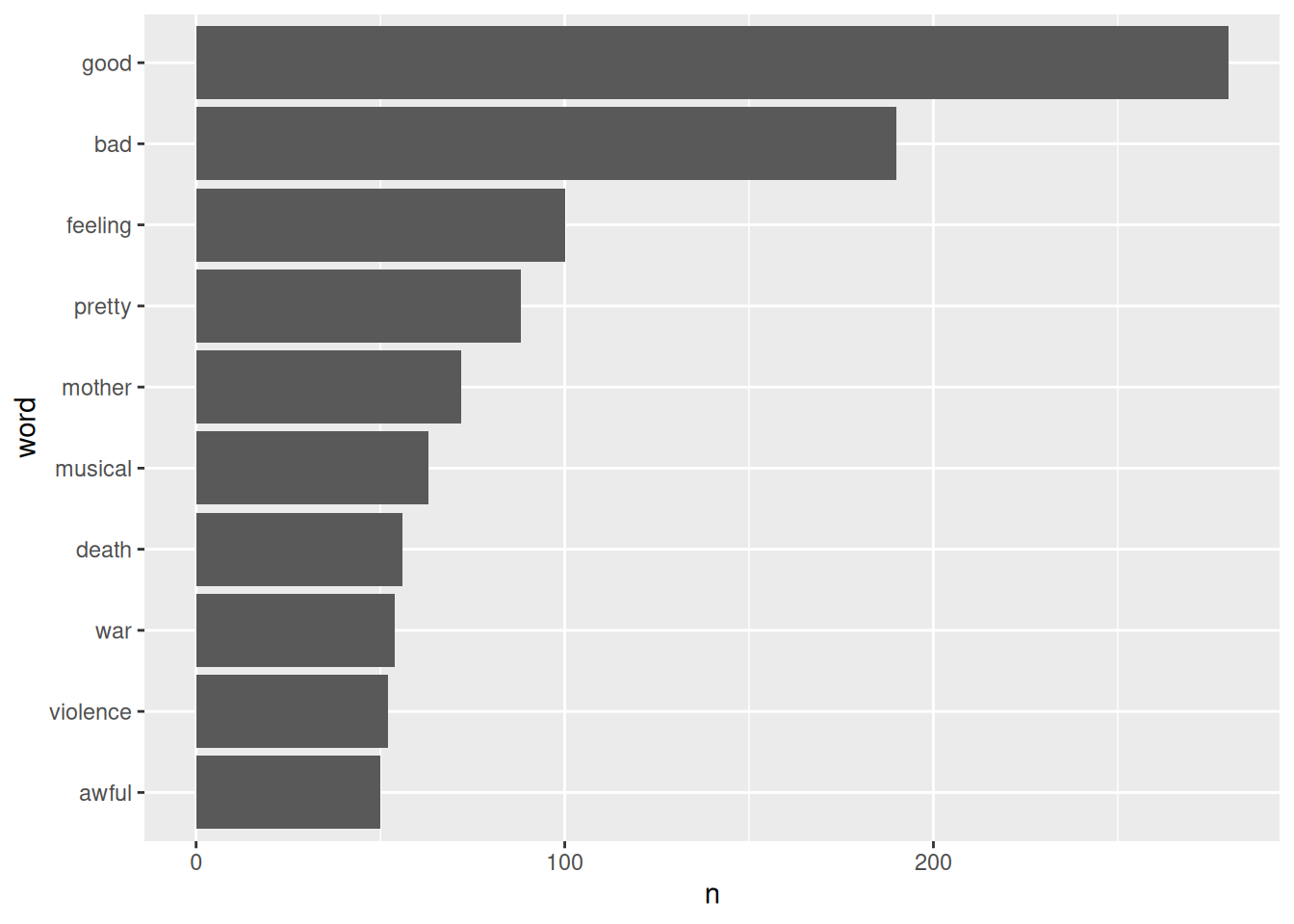
Answerlist
- Falsch
- Falsch
- Richtig
- Falsch
- Falsch
Categories:
- textmining
- imdb
- schoice