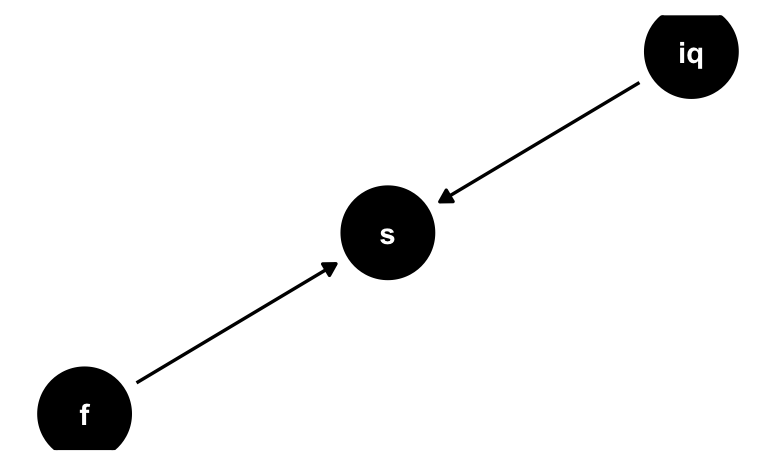
s für Studium, f für fleiss und iq für Intelligenz
Sagen wir, über die Eignung, e, für ein Studium würden nur (die individuellen Ausprägungen) von Intelligenz (iq) und Fleiss (fleiss) entscheiden, s. den DAG in Figure 1.
s für Studium, f für fleiss und iq für Intelligenz
Bei positiver Eignung wird ein Studium aufgenommen (studium = 1) ansonsten nicht (studium = 0).
Eignung (fürs Studium) sei definiert als die Summe von iq und fleiss, plus etwas Glück, s. Listing 1.
set.seed(42) # Reproduzierbarkeit
N <- 1e03
d_eignung <-
tibble(
iq = rnorm(N), # normalverteilt mit MW=0, sd=1
fleiss = rnorm(N),
glueck = rnorm(N, mean = 0, sd = .1),
eignung = 1/2 * iq + 1/2 * fleiss + glueck,
# nur wer geeignet ist, studiert (in unserem Modell):
studium = ifelse(eignung > 0, 1, 0)
)Laut unserem Modell setzt sich Eignung zur Hälfte aus Intelligenz und zur Hälfte aus Fleiss zusammen, plus etwas Glück.
Aufgabe: Zeigen Sie, dass eine Scheinkorrelation entsteht zwischen fleiss und iq, wenn man studium kontrolliert. Zeigen Sie außerdem, dass die Scheinkorrelation verschwindet, wenn man studium nicht kontrolliert.
Hinweise:
library(rstanarm)
library(easystats)Hier ist das Modell, in dem wir nur Studenten betrachten, also studium == 1.
m_eignung <-
stan_glm(iq ~ fleiss,
data = d_eignung %>% filter(studium == 1),
refresh = 0)
hdi(m_eignung)| Parameter | CI | CI_low | CI_high | Effects | Component |
|---|---|---|---|---|---|
| (Intercept) | 0.95 | 0.7004608 | 0.8596029 | fixed | conditional |
| fleiss | 0.95 | -0.5266816 | -0.3634545 | fixed | conditional |
plot(estimate_relation(m_eignung))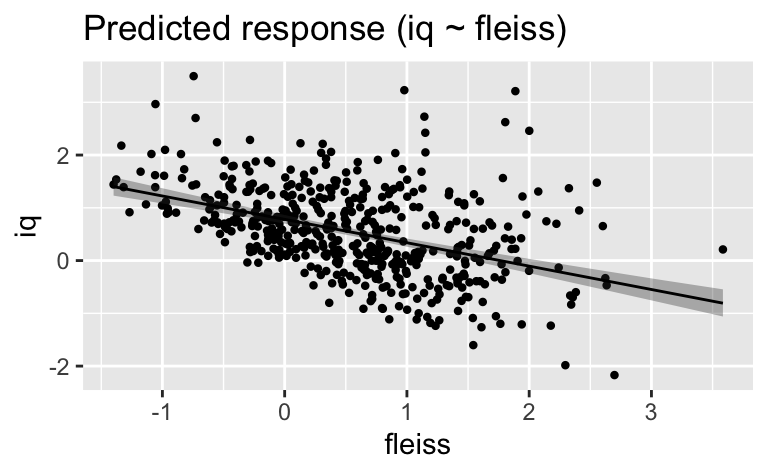
Wie man sieht, gibt es einen Zusammenhang zwischen Fleiss und Intelligenz.
m_eignung_gesamtpop <-
stan_glm(iq ~ fleiss,
data = d_eignung ,
refresh = 0)
plot(estimate_relation(m_eignung_gesamtpop))
hdi(m_eignung_gesamtpop)| Parameter | CI | CI_low | CI_high | Effects | Component |
|---|---|---|---|---|---|
| (Intercept) | 0.95 | -0.0878065 | 0.0344352 | fixed | conditional |
| fleiss | 0.95 | -0.0509851 | 0.0723826 | fixed | conditional |
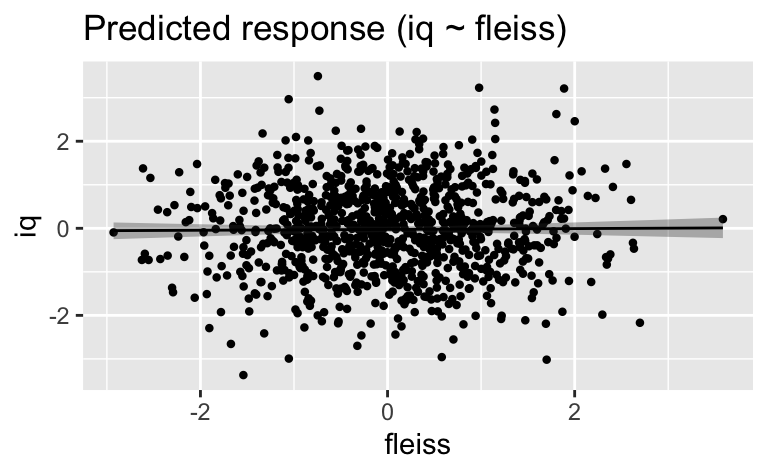
Wie man sieht, löst sich der Zusammenhang zwischen Fleiss und Intelligenz auf, wenn man studium nicht kontrolliert.