library(tidyverse)
library(ggpubr)bayesbox2
bayes
probability
paper
1 Setup
2 Aufgabe
Sie führen ein zweiwertiges (binomiales) Zufallsexperiment \(n\)-mal durch, dabei erzielen Sie \(k\) Treffer. Die Wiederholungen sind unabhängig voneinander, und die Trefferwahrscheinlichkeit \(\pi\) bleibt konstant.
(Eine Münze wiederholt werfen wäre das typische Beispiel für ein solches Zufallexperiment.)
Gehen Sie von folgenden Parameterwerten aus:
n <- 10
k <- 10Welcher Parameterwert \(\pi\) ist am wahrscheinlichsten, wenn Sie keine weiteren Informationen haben?
Sie überprüfen alle 11 Parameterwerte für \(\pi\) von 0 bis 1 (in Schritten von 0.1.)
Um diese Frage zu beantworten, berechnen Sie die Wahrscheinlichkeiten für alle möglichen Parameterwerte \(\pi\) von 0 bis 1 in Schritten von 0.1 anhand einer Bayesbox. Dabei gehen wir von einer Binomialverteilung aus:
\(k \sim Bin(n, \pi)\).
pis <- seq(from = 0, to = 1, by = 0.1) # Parameterwerte
pis [1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0Dann berechnen wir schon mal die Wahrscheinlichkeit der Daten gegeben jeweils eines Parameterwerts:
Likelihood <- dbinom(k, size = n, prob = pis)
Likelihood [1] 0.0000000000 0.0000000001 0.0000001024 0.0000059049 0.0001048576
[6] 0.0009765625 0.0060466176 0.0282475249 0.1073741824 0.3486784401
[11] 1.0000000000Auf dieser Basis erstellen wir eine Bayes-Box, um die Posteriori-Wahrscheinlichkeiten für alle Parameterwerte zu berechnen, s. Listing 2.
d <-
tibble(
# definiere die Hypothesen (die Parameterwerte, p):
p = pis,
# Lege den Priori-Wert fest:
Priori = 1/11) |>
mutate(
# berechne Likelihood für jeden Wasseranteil (Parameterwert):
Likelihood = Likelihood,
# berechne unstand. Posteriori-Werte:
unstd_Post = Likelihood * Priori,
# berechne Evidenz, d.i. die Summe aller unstand. Post-Werte:
Evidenz = sum(unstd_Post),
# berechne stand. Posteriori-Werte (summiert zu 1):
Post = unstd_Post / Evidenz) Die Bayes-Box (Table 1) zeigt, wie sich die Post-Verteilung berechnet.
Leider sind die zentralen Spalten ausgeblendet. 🤬
| id | p | Priori |
|---|---|---|
| 1 | 0.0 | 0.09 |
| 2 | 0.1 | 0.09 |
| 3 | 0.2 | 0.09 |
| 4 | 0.3 | 0.09 |
| 5 | 0.4 | 0.09 |
| 6 | 0.5 | 0.09 |
| 7 | 0.6 | 0.09 |
| 8 | 0.7 | 0.09 |
| 9 | 0.8 | 0.09 |
| 10 | 0.9 | 0.09 |
| 11 | 1.0 | 0.09 |
Aufgabe: Welcher Parameterwert \(\pi\) ist am wahrscheinlichsten laut der Bayesbox?
3 Lösung
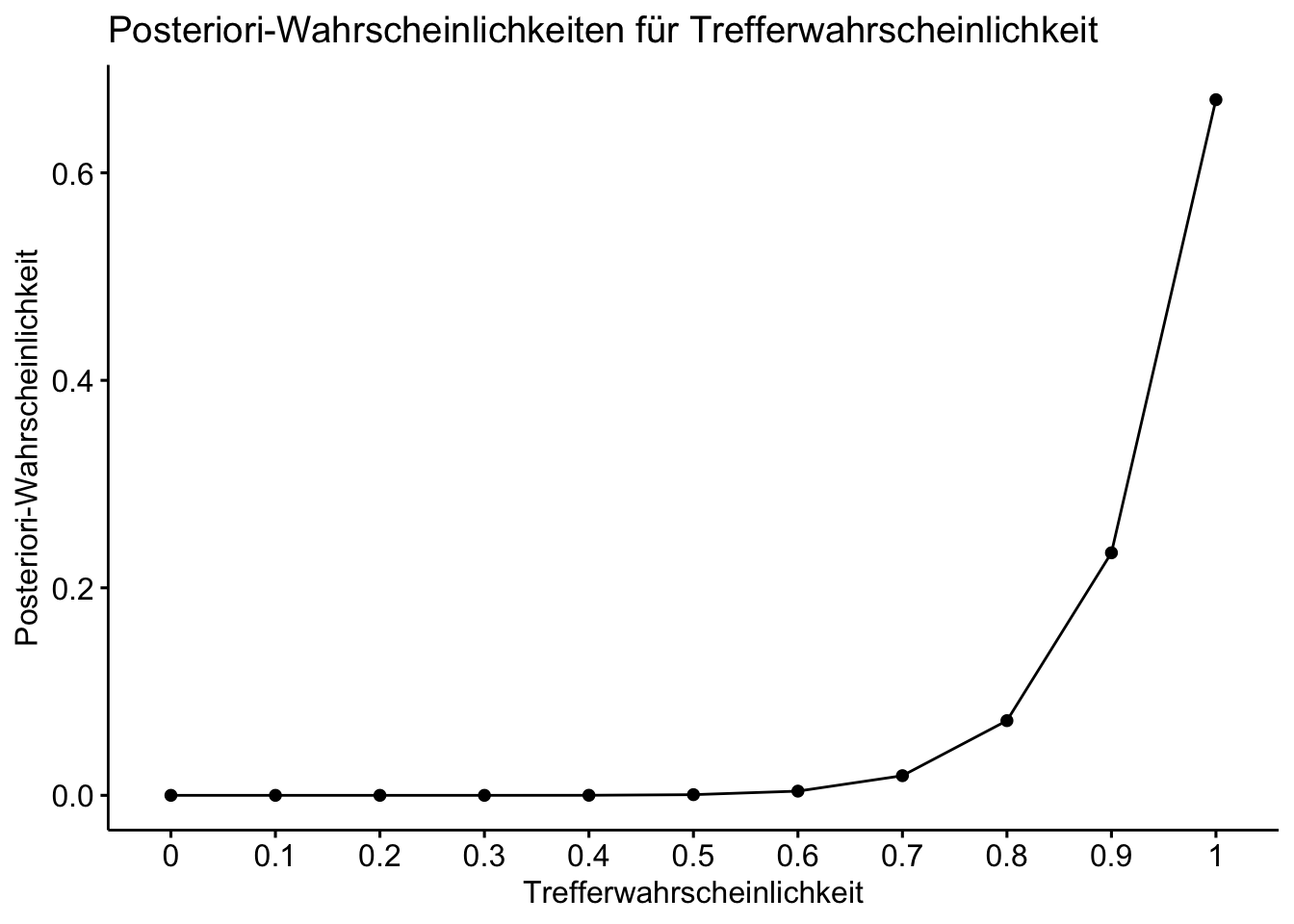
Der wahrscheinlichste Parameterwert \(\pi\) ist derjenige, der die höchste Posteriori-Wahrscheinlichkeit hat.
Bei \(k=n\) Treffer hat \(p=1\) die höchste Posteriori-Wahrscheinlichkeit.
| id | p | Priori | Likelihood | unstd_Post | Evidenz | Post |
|---|---|---|---|---|---|---|
| 1 | 0.0 | 0.09 | 0.00 | 0.00 | 0.14 | 0.00 |
| 2 | 0.1 | 0.09 | 0.00 | 0.00 | 0.14 | 0.00 |
| 3 | 0.2 | 0.09 | 0.00 | 0.00 | 0.14 | 0.00 |
| 4 | 0.3 | 0.09 | 0.00 | 0.00 | 0.14 | 0.00 |
| 5 | 0.4 | 0.09 | 0.00 | 0.00 | 0.14 | 0.00 |
| 6 | 0.5 | 0.09 | 0.00 | 0.00 | 0.14 | 0.00 |
| 7 | 0.6 | 0.09 | 0.01 | 0.00 | 0.14 | 0.00 |
| 8 | 0.7 | 0.09 | 0.03 | 0.00 | 0.14 | 0.02 |
| 9 | 0.8 | 0.09 | 0.11 | 0.01 | 0.14 | 0.07 |
| 10 | 0.9 | 0.09 | 0.35 | 0.03 | 0.14 | 0.23 |
| 11 | 1.0 | 0.09 | 1.00 | 0.09 | 0.14 | 0.67 |
Hier ist eine Visualisierung der Posteriori-Wahrscheinlichkeiten:
ggline(d, x = "p", y = "Post",
xlab = "Trefferwahrscheinlichkeit", ylab = "Posteriori-Wahrscheinlichkeit",
title = "Posteriori-Wahrscheinlichkeiten für Trefferwahrscheinlichkeit",
add = c("point", "smooth"))