library(tidyverse)
diamonds <- read_csv("https://vincentarelbundock.github.io/Rdatasets/csv/ggplot2/diamonds.csv")adjustieren2
regression
lm
qm2
bayes
adjust
qm2-pruefung2023
Exercise
Betrachten Sie folgendes Modell, das den Zusammenhang des Preises (price) und dem Gewicht (carat) von Diamanten untersucht (Datensatz diamonds).
Aber zuerst zentrieren wir den metrischen Prädiktor carat, um den Achsenabschnitt besser interpretieren zu können.
diamonds <-
diamonds %>%
mutate(carat_z = carat - mean(carat, na.rm = TRUE))Dann berechnen wir ein (bayesianisches) Regressionsmodell, wobei wir auf die Standardwerte der Prior zurückgreifen.
library(rstanarm)
library(easystats)
lm1 <- stan_glm(price ~ carat_z, data = diamonds,
chains = 1, # nur ein Mal Stichproben ziehen, spart Zeit (auf Kosten der Genauigkeit)
refresh = 0)
parameters(lm1)| Parameter | Median | CI | CI_low | CI_high | pd | Rhat | ESS | Prior_Distribution | Prior_Location | Prior_Scale |
|---|---|---|---|---|---|---|---|---|---|---|
| (Intercept) | 3933.098 | 0.95 | 3920.805 | 3945.211 | 1 | 0.9998897 | 395.148 | normal | 3932.8 | 9973.599 |
| carat_z | 7755.891 | 0.95 | 7729.898 | 7783.340 | 1 | 1.0000283 | 1327.332 | normal | 0.0 | 21040.850 |
Zur Verdeutlichung ein Diagramm zum Modell:
diamonds %>%
ggplot() +
aes(x = carat_z, y = price) +
geom_point() +
geom_smooth(method = "lm")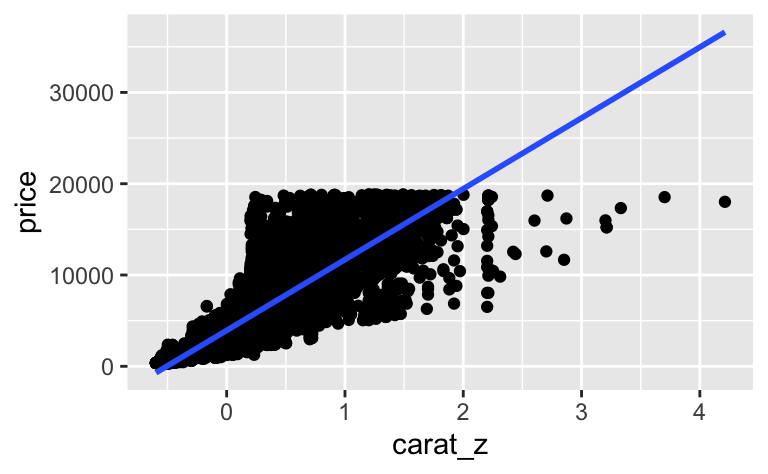
Answerlist
- Was kostet in Diamant mittlerer Größe laut Modell
lm1? Runden Sie auf eine Dezimale. Geben Sie nur eine Zahl ein. - Geben Sie eine Regressionsformel an, die
lm1ergänzt, so dass die Schliffart (cut) des Diamanten kontrolliert (adjustiert) wird. Anders gesagt: Das Modell soll die mittleren Preise für jede der fünf Schliffarten angeben. Geben Sie nur die Regressionsformel an. Lassen Sie zwischen Termen jeweils ein Leerzeichen Abstand.
Hinweis: Es gibt (laut Datensatz) folgende Schliffarten (und zwar in der folgenden Reihenfolge):
diamonds %>%
distinct(cut)| cut |
|---|
| Ideal |
| Premium |
| Good |
| Very Good |
| Fair |
Solution
Unser Modell
lm1schätzt den Preis eines Diamanten mittlerer Größe auf etwa3932.5(was immer auch die Einheiten sind, Dollar vermutlich).price ~ carat_z + cut
Dieses zweite Modell könnten wir so berechnen:
lm2 <- stan_glm(price ~ carat_z + cut, data = diamonds,
chains = 1,
refresh = 0)
parameters(lm2)| Parameter | Median | CI | CI_low | CI_high | pd | Rhat | ESS | Prior_Distribution | Prior_Location | Prior_Scale |
|---|---|---|---|---|---|---|---|---|---|---|
| (Intercept) | 2407.499 | 0.95 | 2336.970 | 2476.942 | 1 | 0.9992733 | 433.6964 | normal | 3932.8 | 9973.599 |
| carat_z | 7870.725 | 0.95 | 7842.525 | 7897.606 | 1 | 1.0024041 | 1150.3728 | normal | 0.0 | 21040.850 |
| cutGood | 1119.217 | 0.95 | 1040.158 | 1199.622 | 1 | 0.9990002 | 498.0572 | normal | 0.0 | 34685.376 |
| cutIdeal | 1798.281 | 0.95 | 1722.665 | 1870.950 | 1 | 0.9992272 | 467.6956 | normal | 0.0 | 20362.277 |
| cutPremium | 1438.331 | 0.95 | 1364.383 | 1513.573 | 1 | 0.9990276 | 492.6073 | normal | 0.0 | 22862.493 |
| cutVery Good | 1507.783 | 0.95 | 1434.045 | 1582.786 | 1 | 0.9991232 | 448.4442 | normal | 0.0 | 23922.148 |
Ein “normales” (frequentistisches) lm käme zu ähnlichen Ergebnissen:
lm(price ~ carat_z + cut, data = diamonds)
Call:
lm(formula = price ~ carat_z + cut, data = diamonds)
Coefficients:
(Intercept) carat_z cutGood cutIdeal cutPremium
2405 7871 1120 1801 1439
cutVery Good
1510 Man könnte hier noch einen Interaktionseffekt ergänzen, wenn man Grund zur Annahme hat, dass es einen gibt.
Categories:
- regression
- lm
- qm2
- bayes
- adjust