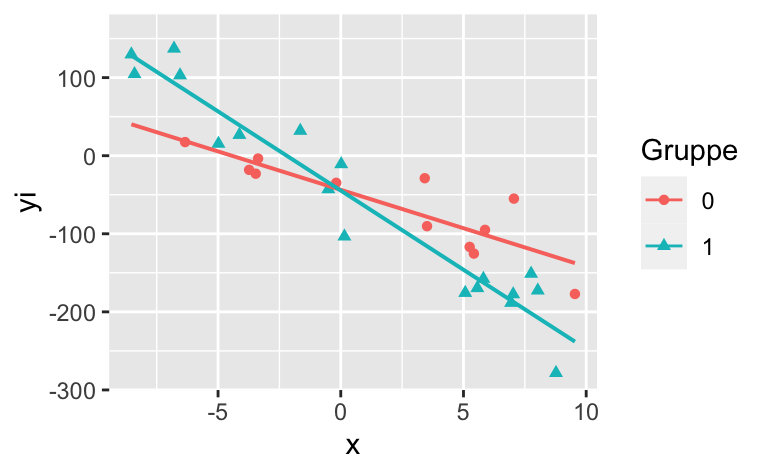
Eine Forscherin berechnet ein Regressionsmodell mit einer metrischen AV y und einer metrischen UV x.
Dazu kommt noch eine Gruppierungsvariable \(g\) (mit den Stufen 0 und 1). Das Modell lautet also: y ~ x + g.
Das folgende Diagramm stellt das Modell dar (vgl. Farbe und Form der Punkte zur Darstellung von g).
Wählen Sie das (für die Population) am besten passende Modell aus der Liste aus!
Hinweis: Ein Interaktionseffekt der Variablen \(x\) und \(g\) ist mit \(xg\) gekennzeichnet.
Answerlist
\(y = 40 + 10\cdot x + 0 \cdot g + 0 \cdot xg + \epsilon\)
\(y = 40 + 10\cdot x + -40 \cdot g + -10 \cdot xg + \epsilon\)
\(y = -40 + 10\cdot x + 0 \cdot g + -10 \cdot xg + \epsilon\)
\(y = -40 + -10\cdot x + 40 \cdot g + -10 \cdot xg + \epsilon\)
Lösung
Der Modellfehler \(\epsilon\) hat den Anteil \(0.1\) im Vergleich zur Streuung von \(y\).
Answerlist
Falsch
Richtig
Falsch
Falsch
Categories:
dyn
regression
lm
schoice
Source Code
---exname: Regression3extype: schoiceexsolution: r mchoice2string(d_five_options$is_correct, single = TRUE)exshuffle: nocategories:- dyn- regression- lm- schoicedate: '2023-05-08'slug: Regression3title: Regression3---<!-- based on Karsten Luebke et al. -->```{r libs, include = FALSE}library(tidyverse)library(mosaic)library(glue)library(testthat)library(exams)``````{r global-knitr-options, include=FALSE}knitr::opts_chunk$set(fig.pos ='H',fig.asp =0.618,fig.width =4,fig.cap ="", fig.path ="",out.width ="75%",fig.align ="center",echo =FALSE,warning =FALSE)```# AufgabeEine Forscherin berechnet ein Regressionsmodell mit einer metrischen AV `y` und einer metrischen UV `x`.Dazu kommt noch eine Gruppierungsvariable $g$ (mit den Stufen `0` und `1`).Das Modell lautet also: `y ~ x + g`.Das folgende Diagramm stellt das Modell dar (vgl. Farbe und Form der Punkte zur Darstellung von `g`). ```{r defs, echo=FALSE}n_set <-c(30, 50, 70)n <-sample(n_set, 1)anteil_g1_set <-c(.4, .5, .6)anteil_g1 <-sample(anteil_g1_set, 1)n_g1 <-floor(anteil_g1 * n)xmin_set <-c(-20,-10)xmin <-sample(xmin_set,1)xmax_set <-c(10,20)xmax <-sample(xmax_set,1)e_set <-c(0.05, .1, .2, .3)e <-sample(e_set, 1)steigung1_set <-c(-10, 10)steigung2_set <-c(-40, 0, +40)achsenabschnitt_set <-c(-40, +40)interaktion_x_g_set <-c(-10, 0, +10)``````{r build-grid, echo = FALSE}d <-expand_grid(steigung1_set, steigung2_set, achsenabschnitt_set, interaktion_x_g_set) %>%mutate(item =glue("$y = {achsenabschnitt_set} + {steigung1_set}\\cdot x + {steigung2_set} \\cdot g + {interaktion_x_g_set} \\cdot xg + \\epsilon$")) ``````{r plot-scatter, echo = FALSE}x <-runif(n, min = xmin, max = xmax)g <-sample(x =c(0, 1), size = n,replace =TRUE,prob =c(anteil_g1, 1-anteil_g1))# only four answer options are supported:d_five_options <- d %>%sample_n(size =4) %>%# choose a "correct" modelmutate(is_correct =sample(x =c(TRUE, rep.int(FALSE, times =nrow(.)-1))))# draw one model as "correct" oned_correct <- d_five_options %>%filter(is_correct ==TRUE)# this is the "correct" model per definitionyhat <- d_correct$achsenabschnitt_set[1] + d_correct$steigung1_set[1] * x + d_correct$steigung2_set[1] * g + d_correct$interaktion_x_g_set[1] * x*gyi <- yhat +rnorm(n, sd =sd(yhat)*e)lm_true <-lm(yi ~ x*g)expect_equal(length(yhat), length(yi))gf_point(yi ~ x, color =~factor(g), shape =~factor(g)) %>%gf_lm() %>%gf_labs(color ="Gruppe", shape ="Gruppe")r2 <-round(rsquared(lm_true), 2)```Wählen Sie das (für die Population) am besten passende Modell aus der Liste aus!*Hinweis*: Ein Interaktionseffekt der Variablen $x$ und $g$ ist mit $xg$ gekennzeichnet.```{r questionlist, echo = FALSE, results = "asis"}answerlist(d_five_options$item, markup ="markdown")```</br></br></br></br></br></br></br></br></br></br># LösungDer Modellfehler $\epsilon$ hat den Anteil $`r e`$ im Vergleich zur Streuung von $y$.```{r solutionlist, echo = FALSE, results = "asis"}answerlist(ifelse(d_five_options$is_correct, "Richtig", "Falsch"), markup ="markdown")```---Categories: - dyn- regression- lm- schoice