p_grid <- seq( from=0 , to=1 , length.out=20 ) # Gitterwerte
prior <- rep( 1 , 20 ) # Priori-Gewichte
likelihood <- dbinom( 6 , size=9 , prob=p_grid )
unstandardisierte_posterior <- likelihood * prior
posterior <- unstandardisierte_posterior / sum(unstandardisierte_posterior)ReThink3e1-7-paper
bayes
probability
post
bayesbox
paper
Aufgabe
Es soll die Posteriori-Verteilung für den Globusversuch erstellt werden. Folgende Parameter wurden verwendet: \(W=6, N = 9\). Für \(\pi\) wurden alle Werte von 0 bis 1 mit einer Auflösung von 20 Parameterwerten.
Dafür wurde folgende Syntax verwendet.
Hier ist die resultierende Bayesbox:
bayesbox(hyps = p_grid, priors = prior, liks = likelihood)| hyps | priors | liks | post_unstand | post_std |
|---|---|---|---|---|
| 0.0000000 | 1 | 0.00 | 0.00 | 0.00 |
| 0.0526316 | 1 | 0.00 | 0.00 | 0.00 |
| 0.1052632 | 1 | 0.00 | 0.00 | 0.00 |
| 0.1578947 | 1 | 0.00 | 0.00 | 0.00 |
| 0.2105263 | 1 | 0.00 | 0.00 | 0.00 |
| 0.2631579 | 1 | 0.01 | 0.01 | 0.01 |
| 0.3157895 | 1 | 0.03 | 0.03 | 0.02 |
| 0.3684211 | 1 | 0.05 | 0.05 | 0.03 |
| 0.4210526 | 1 | 0.09 | 0.09 | 0.05 |
| 0.4736842 | 1 | 0.14 | 0.14 | 0.07 |
| 0.5263158 | 1 | 0.19 | 0.19 | 0.10 |
| 0.5789474 | 1 | 0.24 | 0.24 | 0.13 |
| 0.6315789 | 1 | 0.27 | 0.27 | 0.14 |
| 0.6842105 | 1 | 0.27 | 0.27 | 0.14 |
| 0.7368421 | 1 | 0.25 | 0.25 | 0.13 |
| 0.7894737 | 1 | 0.19 | 0.19 | 0.10 |
| 0.8421053 | 1 | 0.12 | 0.12 | 0.06 |
| 0.8947368 | 1 | 0.05 | 0.05 | 0.03 |
| 0.9473684 | 1 | 0.01 | 0.01 | 0.01 |
| 1.0000000 | 1 | 0.00 | 0.00 | 0.00 |
Dann wurde die Stichproben-Posterior-Verteilung erstellt:
# um die Zufallszahlen festzulegen, damit wir alle die gleichen Zahlen bekommen zum Schnluss:
set.seed(42)
# Stichproben ziehen aus der Posteriori-Verteilung
samples <-
tibble(
p = sample( p_grid , prob=posterior, size=1e4, replace=TRUE)) Hier ist eine Visualisierung der Posteriori-Verteilung:
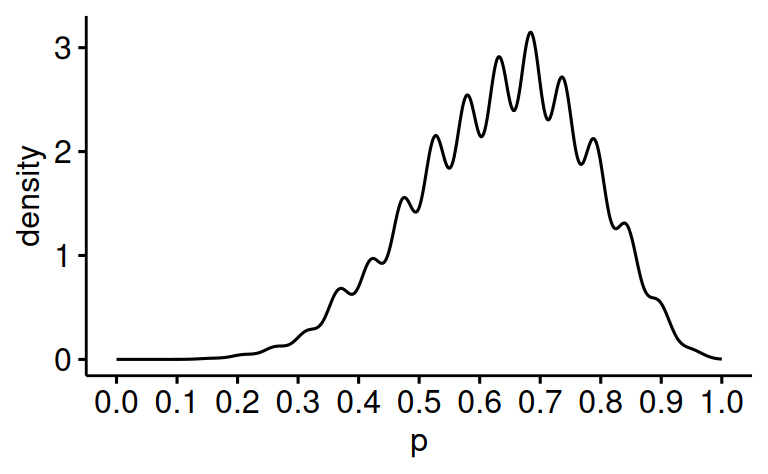
Aufgaben:
Schätzen Sie die Werte zu den folgenden Aufgaben aus der Visualisierung der Post-Veteilung ab!
Wie viel Wahrscheinlichkeitsmasse liegt unter \(p=0.2\)?
Wie viel Wahrscheinlichkeitsmasse liegt über \(p=0.9\)?
Welcher Anteil der Posteriori-Verteilung liegt zwischen \(p=0.2\) und \(p=0.9\)?
Unter welchem Wasseranteil \(p\) liegen 50% der Posteriori-Verteilung?
Über welchem Wasseranteil \(p\) liegen 10% der Posteriori-Verteilung?
Welches schmälstes Intervall von \(p\) enthält 90% der Posteriori-Wahrscheinlichkeit? Wählen Sie das Intervall der folgenden, das am besten passt: \([.1, .9], [.5,.7], [.3,.8]\)
Quelle: McElreath, R. (2020). Statistical rethinking: A Bayesian course with examples in R and Stan (2. Aufl.). Taylor and Francis, CRC Press.
Solution
Es finden sich auch Lösungsvorschläge online, z.B. hier
- Wie viel Wahrscheinlichkeitsmasse liegt unter \(p=0.2\)?
Fast nix, wie man im Diagramm sieht.
Außerdem kann man nachrechnen:
samples %>%
count(p < 0.2)| p < 0.2 | n |
|---|---|
| FALSE | 9995 |
| TRUE | 5 |
- Wie viel Wahrscheinlichkeitsmasse liegt über \(p=0.9\)?
Fast nix, wie man im Diagramm sieht!
samples %>%
count(p > 0.9)| p > 0.9 | n |
|---|---|
| FALSE | 9954 |
| TRUE | 46 |
Naja, so gut 1%!
- Welcher Anteil der Posteriori-Verteilung liegt zwischen \(p=0.2\) und \(p=0.9\)?
Knapp 99%, wie man aus den vorherigen Aufgaben ableiten kann oder sich hier nocheinmal überlegen kann.
Wer nachrechnen (bzw. nachzählen) will:
samples %>%
count(p > 0.2 & p < 0.9) | p > 0.2 & p < 0.9 | n |
|---|---|
| FALSE | 51 |
| TRUE | 9949 |
- Unter welchem Wasseranteil \(p\) liegen 50% der Posteriori-Verteilung?
Puh, das geht optisch nur grob. Gefühlt so bei p = .65
Wer es genauer will: Eine Möglichkeit: Wir sortieren \(p\) der Größe nach (aufsteigend), filtern dann so, dass wir nur die ersten 20% der Zeilen behalten und schauen dann, was der größte Wert ist.
samples %>%
arrange(p) %>%
slice_head(prop = 0.5) %>%
summarise(quantil_20 = max(p))| quantil_20 |
|---|
| 0.6315789 |
Andererseits: Das, was wir gerade gemacht haben, nennt man auch ein Quantil berechnen, s. auch hier. Dafür gibt’s fertige Funktionen in R, wie quantile():
samples %>%
summarise(q_20 = quantile(p, 0.2))| q_20 |
|---|
| 0.5263158 |
- Über welchem Wasseranteil \(p\) liegen 10% der Posteriori-Verteilung?
Wieder ist das optisch nicht so leicht. Aber grob gesagt, so bei p = .8 vielleicht.
Hier die genaue Antwort:
samples %>%
summarise(quantile(p, 0.9))| quantile(p, 0.9) |
|---|
| 0.7894737 |
Mit 90% Wahrscheinlichkeit ist der Wasseranteil höchstens bei 81%.
- Welches schmälstes Intervall von \(p\) enthält 90% der Posteriori-Wahrscheinlichkeit? Wählen Sie das Intervall der folgenden, das am besten passt: \([.1, .9], [.5,.7], [.3,.8]\)
\([.3,.8]\) passt optisch am besten.
Für Detail-Freunde:
library(easystats)
hdi(samples, ci = 0.90)| Parameter | CI | CI_low | CI_high |
|---|---|---|---|
| p | 0.9 | 0.4210526 | 0.8421053 |
Categories:
- bayes
- probability
- post