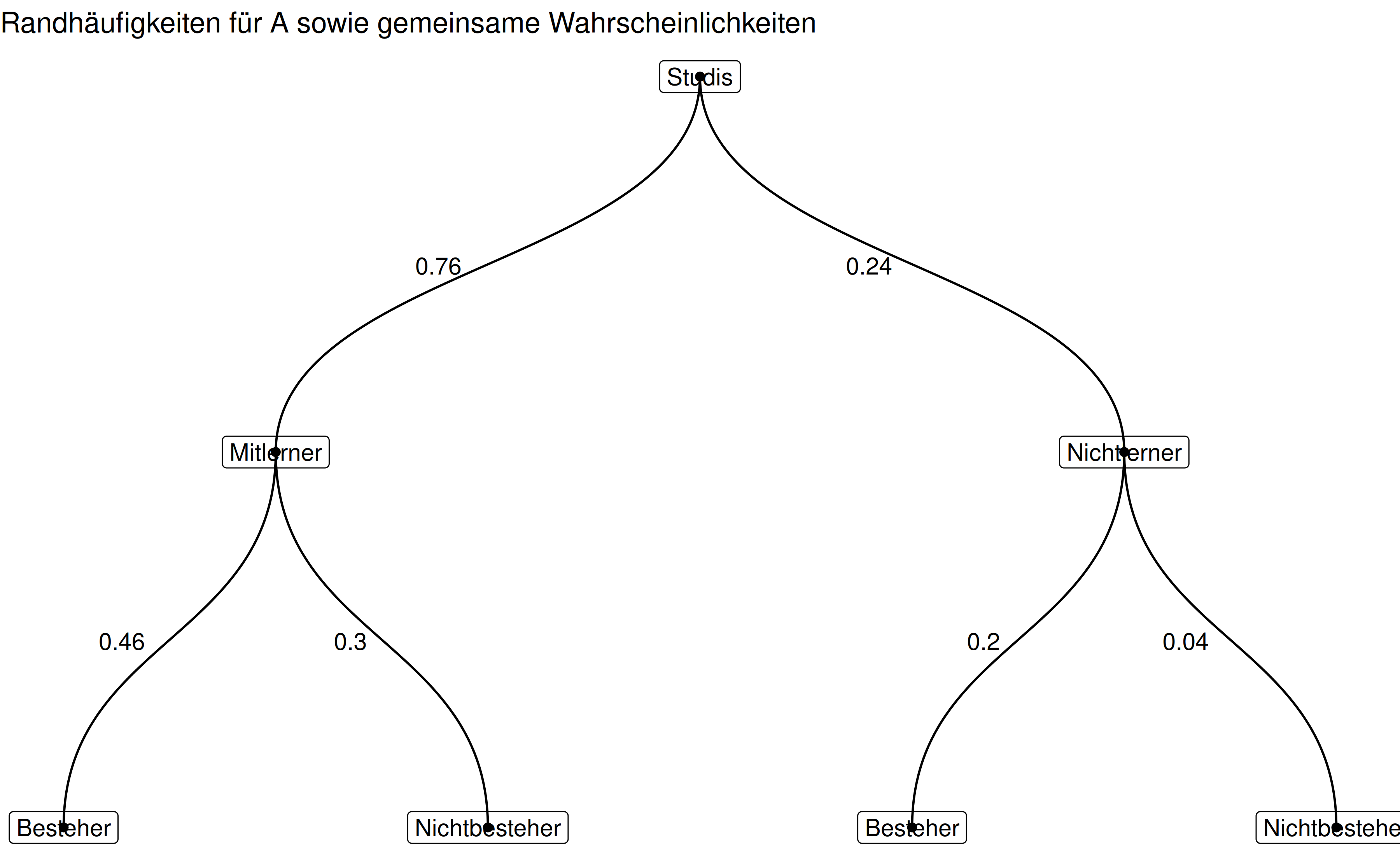
--- exname: Bed-Wskt2 extype: num exsolution: r sol expoints: 1 extol: 0.02 categories: - probability - bayes - num - qm2 - qm2-pruefung2023 date: '2023-11-08' title: Bed-Wskt2 --- ```{r libs, include = FALSE} library (tidyverse)library (glue)library (testthat)library (ggraph)library (igraph)library (gt)``` ```{r global-knitr-options, include=FALSE} :: opts_chunk$ set (fig.pos = 'H' ,fig.asp = 0.618 ,fig.width = 9 ,fig.cap = "" , fig.path = "" ,echo = FALSE ,message = FALSE ,fig.show = "hold" ,out.width = "50%" ,dpi = 200 )``` # Aufgabe ```{r defs} #| echo: false # rbeta(10, 6, 2) <- rbeta (1 , 6 , 2 ) %>% round (2 )<- 1 - A_marg %>% round (2 )<- rbeta (1 , 6 , 2 ) %>% round (2 )<- rbeta (1 , 6 , 2 ) %>% round (2 )<- A_marg * A_distrib %>% round (2 )<- A_marg - AandB %>% round (2 )<- Aneg_marg * Aneg_distrib %>% round (2 )<- Aneg_marg - AnegandB %>% round (2 ) <- AandB + AnegandB %>% round (2 )<- AandBneg + AnegandBneg %>% round (2 )<- tibble (row_ids = c ("A" , "Aneg" , "row_sum" ),B = c (AandB, AnegandB, AandB+ AnegandB),Bneg = c (AandBneg, AnegandBneg, AandBneg+ AnegandBneg)%>% mutate (col_sum = B + Bneg)%>% filter (row_ids == "row_sum" ) %>% select (B, Bneg) %>% mutate (sum_B_Bneg = sum (B, Bneg)) %>% pull (sum_B_Bneg) %>% expect_equal (1 , tolerance = .01 )<- AandB / B_marg %>% round (2 )<- AnegandB / B_marg %>% round (2 )<- AandBneg / Bneg_marg %>% round (2 )<- AnegandBneg / Bneg_marg %>% round (2 )``` ```{r results = "asis"} %>% select (row_ids, B, Bneg) %>% filter (row_ids != "row_sum" ) %>% mutate (across (c (B, Bneg), \(x) sprintf (x, fmt = "%.2f" ))) %>% gt ()``` - Runden Sie auf 2 Dezimalstellen. - Geben Sie Anteile stets in der Form `0.42` an (mit führender Null und Dezimalzeichen).- "Aneg" bezieht sich auf das Komplementärereignis zu A ("A negativ")- Berücksichtigen Sie die üblichen Hinweise des Datenwerks.```{r} <- c ("Zeichnen Sie (per Hand) ein Baumdiagramm, um die gemeinsamen Wahrscheinlichkeiten darzustellen. Weiterhin sollen die Randwahrscheinlichkeiten für $A$ dargestellt sein." ,"Zeichnen Sie (per Hand) ein Baumdiagramm, um diesen Sachverhalt darzustellen." ,"Geben Sie die Wahrscheinlichkeit des gesuchten Ereignisses an." ``` ```{r questionlist, echo = FALSE, results = "asis"} :: answerlist (items, markup = "markdown" )``` </ br > </ br > </ br > </ br > </ br > </ br > </ br > </ br > </ br > </ br > # Lösung ```{r defs-studis} <- #events data frame tibble (from = c ("Studis" ,"Studis" ,"Mitlerner" ,"Mitlerner" ,"Nichtlerner" ,"Nichtlerner" ),to = c ("Mitlerner" ,"Nichtlerner" ,"Besteher" ,"Nichtbesteher" ,"Besteher" ,"Nichtbesteher" )<- unique (c ("Studis" ,"Studis" ,"Mitlerner" ,"Mitlerner" ,"Nichtlerner" ,"Nichtlerner" , "Mitlerner" ,"Nichtlerner" ,"Besteher" ,"Nichtbesteher" ,"Besteher" ,"Nichtbesteher" ))``` ```{r graph1} <- round (c (A_marg, 1 - A_marg, AandB, AandBneg, AnegandB, AnegandBneg), 2 )<- tibble (type = unique (c (edf$ from, edf$ to))<- graph_from_data_frame (d = edf, v = studis_graph, directed = TRUE )#V(studis_graph)$name <- studi_type E (studis_graph)$ studies_props <- studies_props# as_data_frame(studis_graph, what = "edges") ``` ```{r graph2} <- round (c (1 - B_marg, 2 <- tibble (from = c ("Studis" , "Studis" , "Besteher" , "Besteher" , "Nichtbesteher" , "Nichtbesteher" ),to = c ("Besteher" , "Nichtbesteher" , "Lerner" , "Nichtlerner" , "Lerner" , "Nichtlerner" )<- tibble (type = unique (c (edf2$ from, edf2$ to))<- graph_from_data_frame (d = edf2, v = studis_graph_v2, directed = TRUE )E (studis_graph)$ studies_props <- studies_props# as_data_frame(studis_graph, what = "edges") E (studis_graph2)$ studies_prop_cond <- studies_prop_cond``` ```{r} <- vector (mode = "character" , length = 4 )``` ```{r fig.align='center'} <- ggraph (studis_graph, layout = 'dendrogram' , circular = FALSE ) + geom_edge_diagonal (aes (label = studies_props), hjust = 1.5 ) + geom_node_point () + geom_node_label (aes (label = name)) + theme_void () + labs (title = "Randhäufigkeiten für A sowie gemeinsame Wahrscheinlichkeiten" )``` ```{r fig.align='center'} <- ggraph (studis_graph2, layout = 'dendrogram' , circular = FALSE ) + geom_edge_diagonal (aes (label = studies_prop_cond), hjust = 1.5 ) + geom_node_point () + geom_node_label (aes (label = name)) + theme_void () + labs (title = "Randhäufigkeiten für B sowie bedingte Wahrscheinlichkeiten" )``` ```{r} <- A_cond_B %>% round (2 ) %>% as.character ()``` `r sol` ```{r echo = TRUE} <- (AandB / B_marg) %>% round (2 )<- (AnegandB / B_marg) %>% round (2 )<- (AandBneg / Bneg_marg) %>% round (2 )<- (AnegandBneg / Bneg_marg) %>% round (2 )``` `r A_marg` $.`r B_marg` $.`r AandB` $.`r A_cond_B` $.`r Aneg_cond_B` $.`r A_cond_Bneg` $.`r Aneg_cond_Bneg` $.- probability- conditional- bayes- num